
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- rag parsing
- fp16
- qlora
- anomaly detection
- LLaVA
- visual instruction tuning
- 데이터 파싱
- 파인튜닝
- fp32
- bf16
- Non-Maximum Suppression
- Cross Entropy Error
- 딥러닝
- 활성화함수
- multi-query
- Mean squared error
- 오차역전파
- 이상탐지
- gemma3
- pdf parsing
- rag-fusion
- 활성화 함수
- LLM
- fine tuning
- 합성곱 신경망
- LLM 패러다임
- deep learning
- Nested Learning
- rrf
- Time Series
- Today
- Total
Attention, Please!!!
[Image Classification] 개념과 알고리즘(LeNet5~ResNet) 이해하기 본문
※ 앞선 게시물에서는 합성곱 신경망(Convolutional Neural Networ)에 대해 알아보았습니다. CNN은 대체적으로 이미지 처리와 관련된 작업에 사용되지만, 이는 크게 3가지의 유형(이미지 분류, 객체 인식, 이미지 분할)으로 나뉘게 됩니다. 본 게시물에서는 이미지 분류에 사용되는 알고리즘과 구현 방법에 대해 알아보도록 하겠습니다.
💡 이미지 분류(Image Classifcation)

Image Classification는 이미지 내의 객체나 장면 등을 분류하는데 사용되는 알고리즘입니다. 예를 들어, 강아지와 고양이 사진이 주어졌을 때, 각각을 고양이와 강아지로 분류하는 것이 가장 일반적인 예입니다. 그렇다면 이미지 분류에 주로 사용되는 합성곱 신경망의 유형을 알아보도록 하겠습니다.
📌 LeNet-5
LeNet-5는 수표에 쓴 손글씨 숫자를 인식하기 위해 딥러닝 구조 LeNet-5가 발표되었으며, 이는 현재 CNN의 초석이 되었습니다. LeNet-5는 간단하게 합성곱(Convolutional)과 다운 샘플링(혹은 풀링)을 반복적으로 거치면서 마지막에 Fully Conntected Layer를 통해 분류를 수행합니다. 그럼 아래의 그림을 통해 LeNet-5의 구조에 대해 알아보도록 하겠습니다.
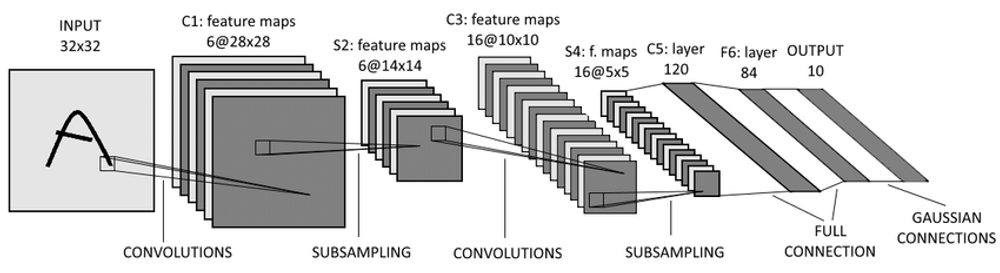
또한, LeNet-5의 신경망 Sumamry 이므로 구현하실 때 참고하시길 바랍니다.

LeNet-5는 32x32 크기의 이미지에 3개의 합성곱층(Convolutional Layer)과 서브샘플링 레이어(Subsampling Layer or Max-Pooling Layer)이 쌍으로 두번 적용된 후 완전연결층(Fully Connected Layer)을 거쳐 이미지가 분류되는 신경망입니다. 또한 활성화 함수는 Hyperbolic Tangent 함수를 사용하는 점 참고하시길 바랍니다.
✔️ 서브샘플링을 하는 이유 : 사람 글씨의 픽셀을 따져보면, 글씨의 위치와 변형에 대한 경우의 수는 매우 많으며 이를 학습하는 것은 너무나도 비효율적입니다. 이에 서브샘플링 통해 글씨의 위치이동, 회전, 부분적인 변화 및 왜곡에 대한 강한 인식력을 키워 글씨의 형태를 비슷하게 만들기 위함입니다.
📌 AlexNet
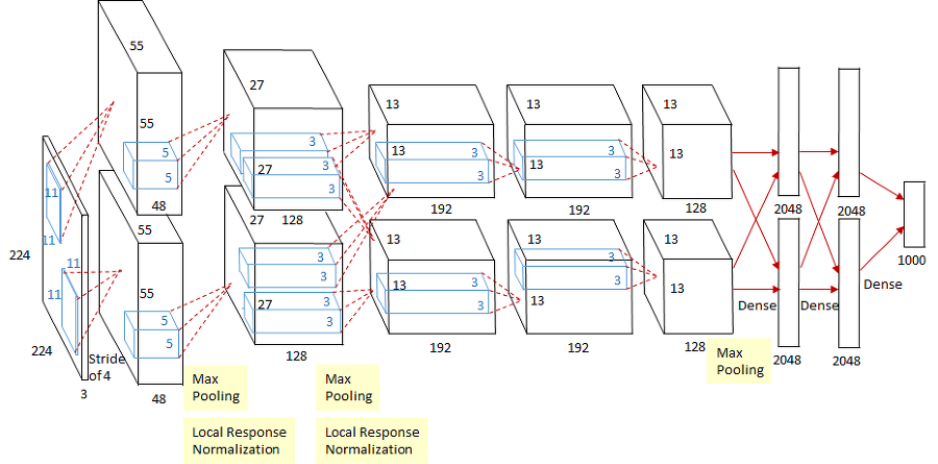
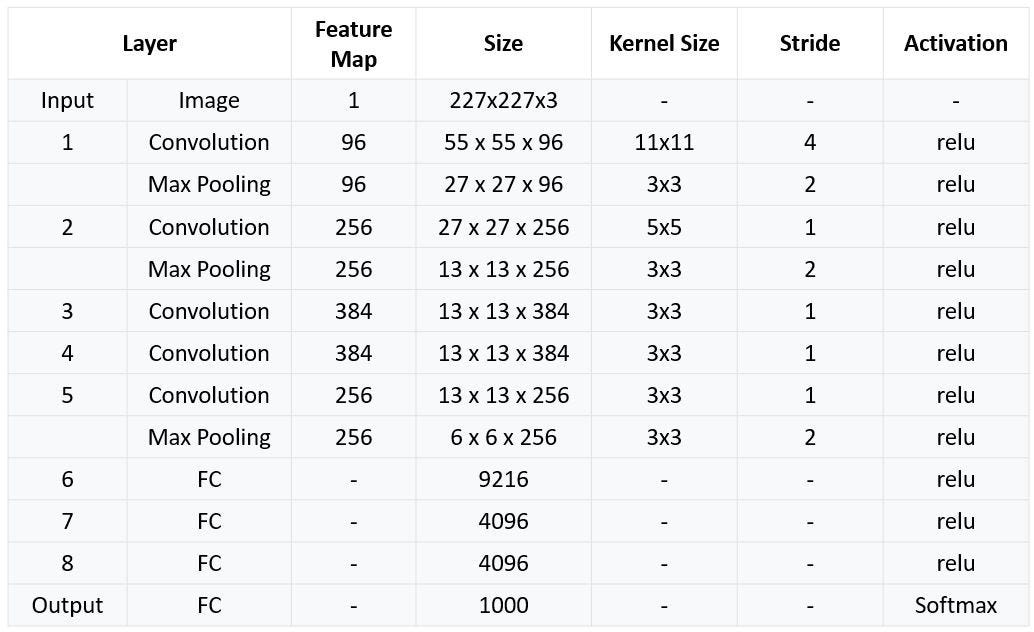
AlexNet은 화상 인식 대회인 "ILSVRC 2012"에서 우승한 CNN의 구조입니다. AlexNet은 224x224x3 크기의 RGB 이미지에 합성곱층 다섯 개, 풀링층 2개와 완전연결층 세개로 구성되어 있으며, 맨 마지막 완전연결층은 카테고리 1000개를 분류하기 위해 소프트맥스 활성화 함수를 사용합니다. 또한 합성곱 층에서는 ReLU 활성화 함수를 사용하는 점 참고하시길 바랍니다.
각 계층의 구조적 세부 사항은 아래의 사진을 참고하시길 바랍니다.
전체적으로 보면 GPU 두개를 기반으로 한 병렬 구조인 점을 제외하면 LeNet-5와 크게 다르지 않습니다. AlexNet의 첫번째 계층을 거치면서 GPU-1에서는 주로 컬러와 상관없는 정보를 추출하기 위한 커널이 학습되고, GPU-2에서는 주로 컬러와 관련된 정보를 추출하기 위한 커널이 학습됩니다. 각 GPU의 적용 결과는 아래와 같습니다.

📌 VGGNet
VGGNet은 2015년에 ICLR 게재된 논문에 의해 처음으로 발표되었습니다. 이 알고리즘의 핵심은 네트워크의 깊이를 깊게 만드는 것이 성능에 어떠한 영향을 미치는지 확인하고자 탄생하게 되었습니다. 이에 VGGNET 연구팀은 필터/커널의 크기를 가장 작게 만들어, 각 계층을 거치는 이미지의 사이즈가 순식간에 축소되는 것을 방지하기 위해 필터/커널의 크기를 3x3으로 고정하였습니다.
그렇다면, 굳이 왜 필터/커널 크기를 3x3으로 고정하였을까요? 아래 그림을 통해 알아보도록 하겠습니다.

3x3 필터/커널(Stride = 1)를 두개를 쌓게 된다면, 5x5 필터/커널의 성능과 같아집니다. 이에 3x3 커널/필터를 깊게 쌓으면 쌓을수록 Receptive Field의 영역을 넓어집니다. 그럼 이게 도대체 왜 좋은걸까요?
만약에 한 개의 층이 7x7 필터로 구성 되어있고, 세 개의 층이 3x3필터로 구성되어 있다고 가정을 해보겠습니다. 그렇다면, 한 개의 층에서 나오는 Parameter의 개수는 49C^2이고, 세 개의 층에서 나오는 파라미터 개수는 27C^2가 됩니다. 메모리 측면에서 고려한다면 파라미터 수가 적은 것이 더 효율적일 것 입니다.
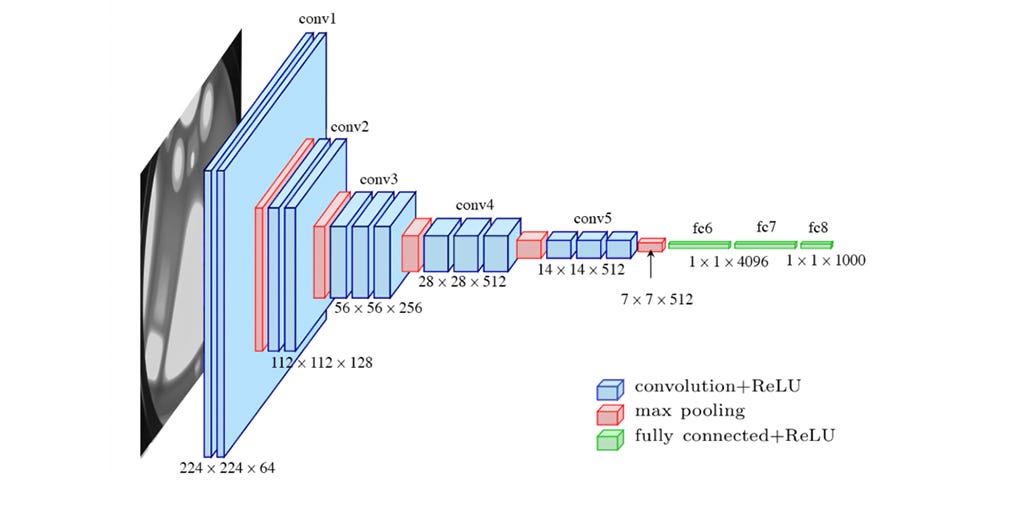
VGGNet은 네트워크 계층의 총 개수에 따라 여러 유형의 VGGNet(VGG16, VGG19 등) 존재하며, 주목 해야할만한 사항은 다음과 같습니다. VGGNet은 224x224 크기의 이미지, 2x2 크기의 최대 풀링 커널, 스트라이드는 2이라는 점입니다. 또한, 마지막 계층은 Softmax 활성화 함수를 사용하고, 나머지 Convolutional Layer은 ReLU 활성화 함수를 사용합니다.
아래의 사진을 통해 여러 유형 VGGNet 모델의 네트워크 Summary에 대해 알아보도록 하겠습니다.

여태까지 알아보았던 LeNet-5와 AlexNet의 구조보다 매우 복잡하다는 것을 볼 수 있습니다. VGG11은 가장 간단한 VGGNet 네트워크이며, VGG19를 구현하고자 한다면, 층을 더욱 깊게 쌓아 올리시면 됩니다.
📌 GoogLeNet
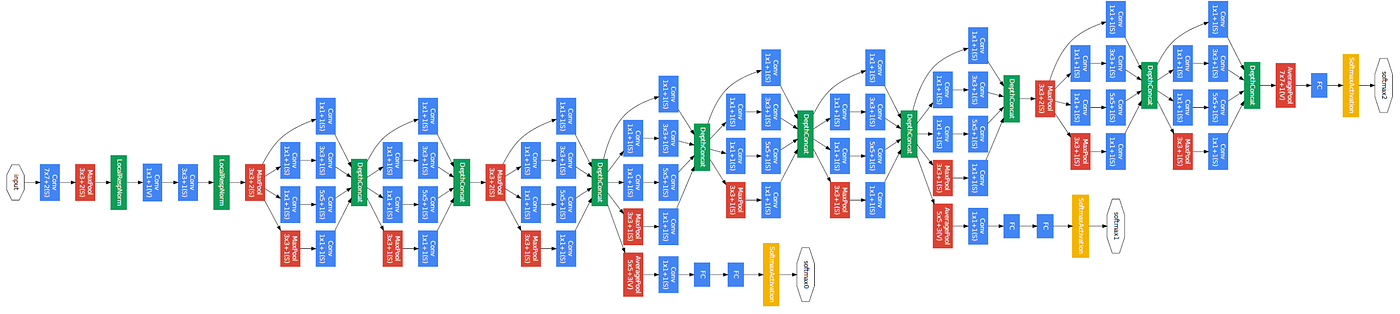
Convolutional Neural Network(CNN)의 성능을 향상시키는 원초적인 방법은 계층(Layer)의 크기를 늘리는 방법입니다. 하지만 AlexNet 알고리즘와 같이 Layer의 크기가 16 혹은 19가 된다면 trainable parameter 수가 급격하게 증가하게 되며, Overfitting의 문제를 초래하게 됩니다. 또한 두 개의 GPU를 사용한다고 한들, 수십 시간동안 학습을 해야한다는 단점이 있습니다. 따라서, 이러한 문제점을 해결하기 위해 GoogLeNet 연구진들은 Network의 구조적인 변화에 대해 고민하였고, Inception이라는 모듈로 구성된 GoogLeNet을 고완하게 되었습니다. 이에 Sparsely Connected 구조로 구성하여 Layer들간의 상관관계 통계분석을 활용하여 최적의 네트워크를 구성할 수 있다고 주장했습니다. 이에 대해 조금 더 깊게 알아보도록 하겠습니다.
✔️ Inception Module

Inception Module의 핵심 아이디어는 이전 층의 출력을 입력으로 받아 세 개의 Convolution Layer과 한 개의 Max-Pooling을 거친 후 여러 개의 필터를 병렬로 이어붙이게 됩니다. 여러 스케일의 Convolution 연산을 활용하게 된다면, 여러가지의 특징을 뽑아낼 수 있다는 장점이 있습니다. 하지만 이러한 연산은 너무나도 많은 파라미터 수의 계산과 메모리 값을 할당시키게 됩니다. 이에 GoogLeNet 연구진은 이러한 문제점을 해결하기 위해 그림(b)의 1x1 Convolution를 추가하게 되었으며, 이는 Dimension Reduction을 목적으로 사용합니다.

또한, 3X3 크기의 필터를 하나만 사용하여 이미지 특성을 찾는다면, 같은 이미지임에도 불구하고 위치뿐만 아니라 비율이 바뀌므로 손실되는 특징이 많아집니다. 이러한 관점에서 Inception Module를 사용한다면 최대한 효율적이며 학습 능력을 극대화 할 수 있습니다.
📌 ResNet
일반적으로 신경망 깊이가 깊어질수록 딥러닝의 성능은 좋아질 것 같지만, Vanishing Gradient 문제로 막상 그렇진 않습니다. ResNet의 저자인 Microsoft 연구진은 신경망의 깊이가 깊어질수록 성능이 좋아지다가 일정한 단계에 다다르면 오히려 성능이 급격하게 떨어진다고 언급하였습니다. 아래의 사진과 같이 네트워크 55층과 20층을 비교하였을 때, 20층의 성능이 비교적으로 좋은 것 확인할 수 있습니다. 즉, 최적화에 어려움이 있다는 가설을 주장하였습니다.

✔️ Residual Module

AlexNet과 GoogLeNet 네트워크의 문제점은 층이 깊어짐에 따라 발생하는 Overfitting(=과적합) 및 Gradient Vanishing(=기울기 소실)입니다. 기존 방식의 신경망은 합성곱 층이 개별적으로 분리 되어있으며, 가중치 값들을 개별적으로 학습하기 때문에 네트워크의 수렴 난이도는 어려워집니다. 왜냐하면 연산 중에 의미 없는 파라미터의 수가 발생하면 연쇄적으로 다음 층에 영향을 미치기 때문입니다. 이를 해결하는 방법이 ResNet의 핵심인 Identity Mapping(=Skip Connection)을 사용하는 Residual Block를 제안하면서, 층이 깊어짐에 따라 기울기 소실 & 과적합의 문제를 해결할 수 있게 됩니다.
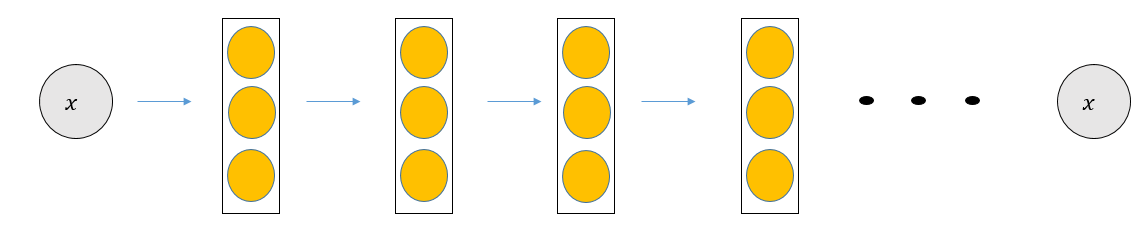
위의 그림처럼 Identity Block(네트워크의 입력과 출력이 동일한 차원을 가짐)를 구성하면 되지만, ReLU와 같은 비선형 Layer으로 인하여 Identity Mapping에 대한 어려운점이 있습니다.
Identity Mapping은 입력값과 출력값이 동일한 항등 함수를 뜻합니다. 예를 들어 ReLU와 같은 비선형 활성화 함수를 사용하게 된다면, 입력값이 음수인 경우 0으로 만들어버리므로, 항등 함수의 고유적인 의미를 잃어버리게 됩니다. 이에 역전파 과정에서 Gradient Vanishing 문제가 발생하게 되므로, 학습하는데 어려움을 줄 수 있기 때문입니다.
그래서 나온 방법이 아래와 같은 그림입니다.
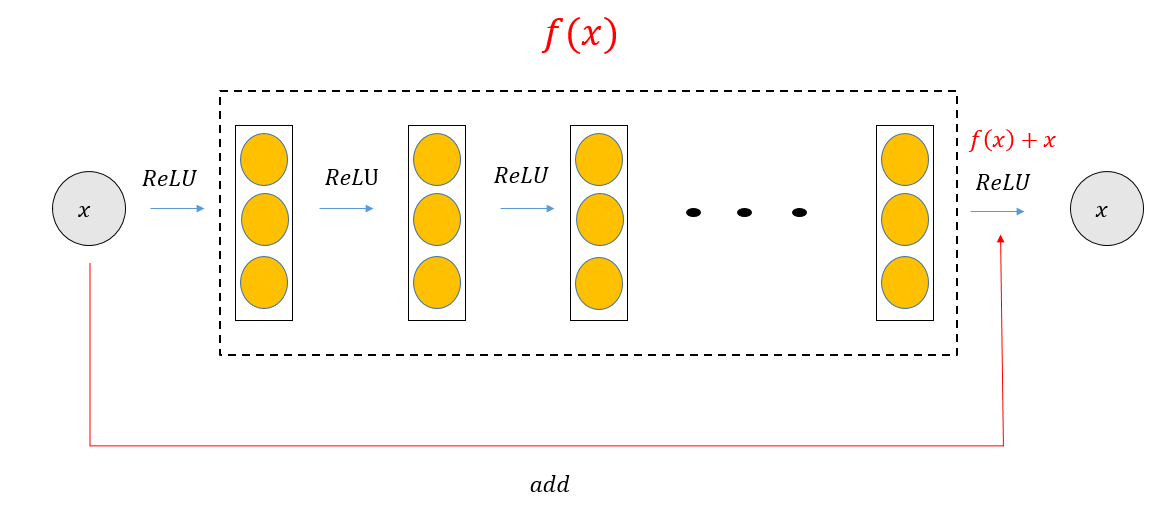
기존의 신경망은 x를 타겟값 y로 매핑하는 함수 H(x)를 얻는 것이 목표였다면, ResNet은 F(x)+x를 최소화하는 것이 가장 큰 목표입니다. 현시점에서 X는 변할수 없는 값이므로, F(x)를 0에 가깝게 만드는 것이 목적이 됩니다. F(x)가 0에 가까워질수록 출력과 입력이 모두 X에 가까워지며 F(x) = H(x) - x 입니다. 이에 F(x)를 0과 가깝게 한다는 말은 H(x) - x를 0과 가깝게 하는 것과 동일한 의미를 지닙니다.
즉, 스킵연결의 핵심은 상류의 기울기에 아무런 수정도 가하지 않고 "그대로" 흘리는 것 입니다. 그래서 스킵 연결로 기울기가 작아지거나 커질 걱정 없이 앞층에 "의미 있는 기울기"가 전해지리라 기대할 수 있습니다. 이에 층을 깊게 할수록 기울기가 작아지는 소실 문제를 이 스킵 연결을 통해 해결할 수 있습니다.
'Computer Vision' 카테고리의 다른 글
| [Object Detection] Slide Window & Selective Search 개념 (0) | 2024.03.16 |
|---|---|
| [Object Detection] 개념 정리 (0) | 2024.03.15 |
| [딥러닝 모델] CNN im2col 이해하기 (0) | 2024.02.23 |
| [CNN] 합성곱 신경망 Pytorch 구현 (0) | 2024.02.21 |
| [CNN] 합성곱 신경망 개념 정리 (1) | 2024.02.18 |