
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- qlora
- 파인튜닝
- Cross Entropy Error
- deep learning
- rag-fusion
- 합성곱 신경망
- LLM
- 딥러닝
- fine tuning
- multi-query
- anomaly detection
- pdf parsing
- 활성화함수
- rrf
- rag parsing
- 데이터 파싱
- LLaVA
- fp16
- Time Series
- 활성화 함수
- 오차역전파
- 이상탐지
- Mean squared error
- visual instruction tuning
- Non-Maximum Suppression
- LLM 패러다임
- fp32
- gemma3
- Nested Learning
- bf16
- Today
- Total
Attention, Please!!!
Contrastive Learning을 통한 임베딩 모델의 성능 극한으로 끌어올리기 본문
LLM에서 임베딩은 텍스트의 의미를 수치적으로 얼마나 잘 표현하는지에 따라 모델의 언어 이해 및 생성 능력을 결정짓는 핵심적인 요소이다. Next Token Prediction 기반의 Causal Masking 기법을 사용하는 모델이든, 문장 전체를 한 번에 보고 특정 단어의 의미를 그 단어의 앞과 뒤에 있는 모든 단어를 동시에 참고하는 Masked Language Model이 있다. 전반적으로 LLM 시장을 아우르는 두 개의 모델은 단어나 문맥의 미묘한 차이를 정확히 포착하는 고품질 임베딩 모델이 필수적이다. 하지만 "How Contextual are Contextualized Word Representations?" 논문에 따르면, 모델이 상위 계층을 거치면 거칠수록 문맥 특정성이 높아진다고 지적한다. 즉, 모델의 깊은 층에서 나온 임베딩 일수록 같은 단어라도 문맥에 따라 더 뚜렷하게 구별되는, 즉 자기 유사도(self-similarity)가 낮은 표현을 만들어낸다고 주장하였다. 이는 모델이 단순히 단어의 표면적인 의미를 넘어, 문맥 속에서 단어가 갖는 미묘한 의미 변화를 학습하고 있음을 시사한다. 이에 따라 본 게시물에서는 이러한 문제점을 개선할 수 있는 SimCSE : Simple Contrastive Learning of Sentence Embeddings 논문에 대해 알아보고자 한다.
Contrastive Learning의 핵심
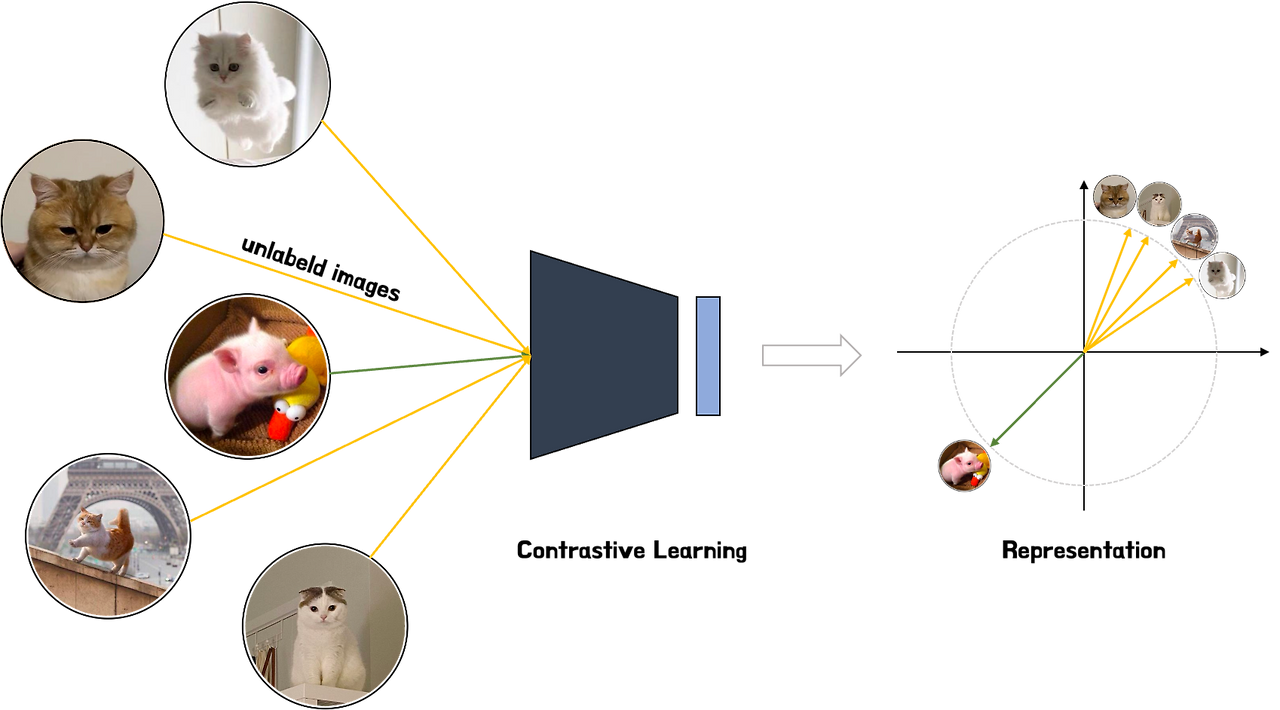
Contrastive Learning은 Self-Supervised Learning으로, 데이터의 고유한 특징을 효과적으로 학습하는 것을 목표로 한다. 핵심 아이디어는 생각보다 간단하다. 서로 유사한 데이터의 임베딩은 가깝게 만들고, 서로 유사하지 않은 임베딩은 멀게 만들도록 모델을 학습 시키는 것이다. 그렇다면, Contrastive Learning이 어떠한 이유로 인해 필요해졌는지 알아볼 필요가 있다. 기존의 지도 학습 같은 경우, 대량의 레이블 데이터가 필요한데, 이를 수집하는 과정에 많은 비용 혹은 시간이 소요가 된다. 반면에 비지도 학습은 레이블이 없이 모델을 학습할 수 있지만, 학습된 데이터의 표현이 굉장히 제한적이다. 이러한 문제점을 개선하기 위해 고안된 방법이 바로 Contrastive Learning이다.
따라서, Contrastive Learning은 레이블 없이도(또는 최소한의 레이블로) 데이터 자체의 내재된 구조를 파악하고, Downstream Task에 유용한 데이터(임베딩)를 학습하는 데 매우 효과적이다. 특히, 모델이 데이터의 변별적인(Discriminative) 특징을 학습하도록 도움을 준다. 즉, 유사한 것은 당기고 다른 것은 밀어내는 단순한 원칙을 반복함으로써, 모델은 데이터의 본질을 가려내는 기준을 스스로 학습한다.
이때 모델이 가깝게 만들어야 할 학습 대상을 Positive Pair, 멀게 만들어야 할 대상을 Negative Pair이라고 한다. 예를 들어, 원본 고양이 이미지와 그 이미지를 약간 변형(회전, 자르기 등)한 이미지는 긍정 쌍이 되어 모델은 둘의 특징을 가깝게 만든다. 반면, 고양이 이미지와 전혀 상관없는 강아지 이미지는 부정 쌍이 되어 둘의 특징을 최대한 멀리 밀어낸다.
이 과정을 통해 모델은 객체의 정체성(고양이의 귀, 수염)을 나타내는 특징은 보존하고, 부수적인 변화(배경, 각도)는 걸러내는 정교한 분별력을 갖추게 되는 것이다.
그렇다면, LLM에서는 어떻게 적용되는거지?
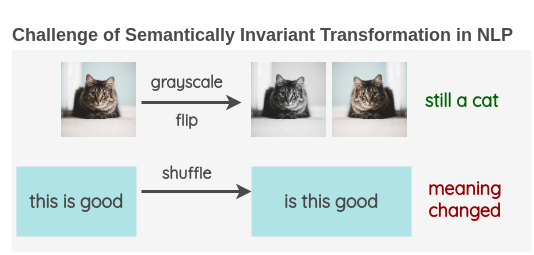
이미지 분야에서는 데이터 증강을 통해 이미지 하나로 수많은 학습 데이터 쌍을 만들어낸다. 예를 들어, 고양이 사진 원본을 약간 자르거나(Crop), 회전시키거나(Rotate), 색감을 바꾸는 등 다양한 변형을 가한다. 이렇게 변형된 이미지들은 픽셀상으로는 원본과 다르지만, 여전히 같은 고양이라는 본질적인 의미를 공유한다. 이에 모델은 이들을 Positive Pair으로 인식하여 벡터 공간에서 서로의 거리를 좁히도록 학습하게 된다. 반면에, 전혀 다른 대상인 강아지나 자동차 사진은 Negative Pair로 거리를 최대한 멀리 밀어내도록 학습한다. 이를 통해 모덿은 표면적인 변화에 흔들리지 않고 대상의 핵심적인 특징을 식별하게 되는 것이다.
과연 이러한 논리를 언어에 적용할 수 있을까? 여기에는 근본적인 어려움이 따른다. 예를 들어 아래와 같은 문장이 있다고 가정을 해보자.
- Sequence 1: "와 벌써 12월 23일이야! 곧 크리스마스네!"
- Sequence 1* (증강: 단어 삭제): "12월 23일이야! 곧 크리스마스네!"
- Sequence 1* (증강: 순서 변경): "곧 크리스마스네! 와 12월 23일이야 벌써."
이미지 같은 경우 연속적인 픽셀로 이루어진 것과 달리, 언어는 단어와 문법 구조로 구성된 Discrete한 데이터이다. 위 예시처럼 "와, 벌써" 단어들을 임의로 삭제하거나, 두 절의 문장을 아예 바꿔버린다면 기존 문장이 가진 시간이 빠르다는 놀라움과 기대에 찬 설렘이라는 뉘앙스가 사라지며, 핵심적인 의미가 크게 훼손이 된다. 이는 모델이 전혀 다른 뉘앙스의 문장을 같은 의미로 오인하게 만들어, 잘못된 관계를 학습하게 될 위험이 커지게 된다.
그럼, 언어를 사용하는 LLM 분야에서는 어떻게 Augmentation을 하고, 이에 대한 positive pair/negative pair를 만들어서 학습을 해야할까? 라는 질문을 하게된다.
SimCSE: Simple Contrastive Learning of Sentence Embedding (Link)
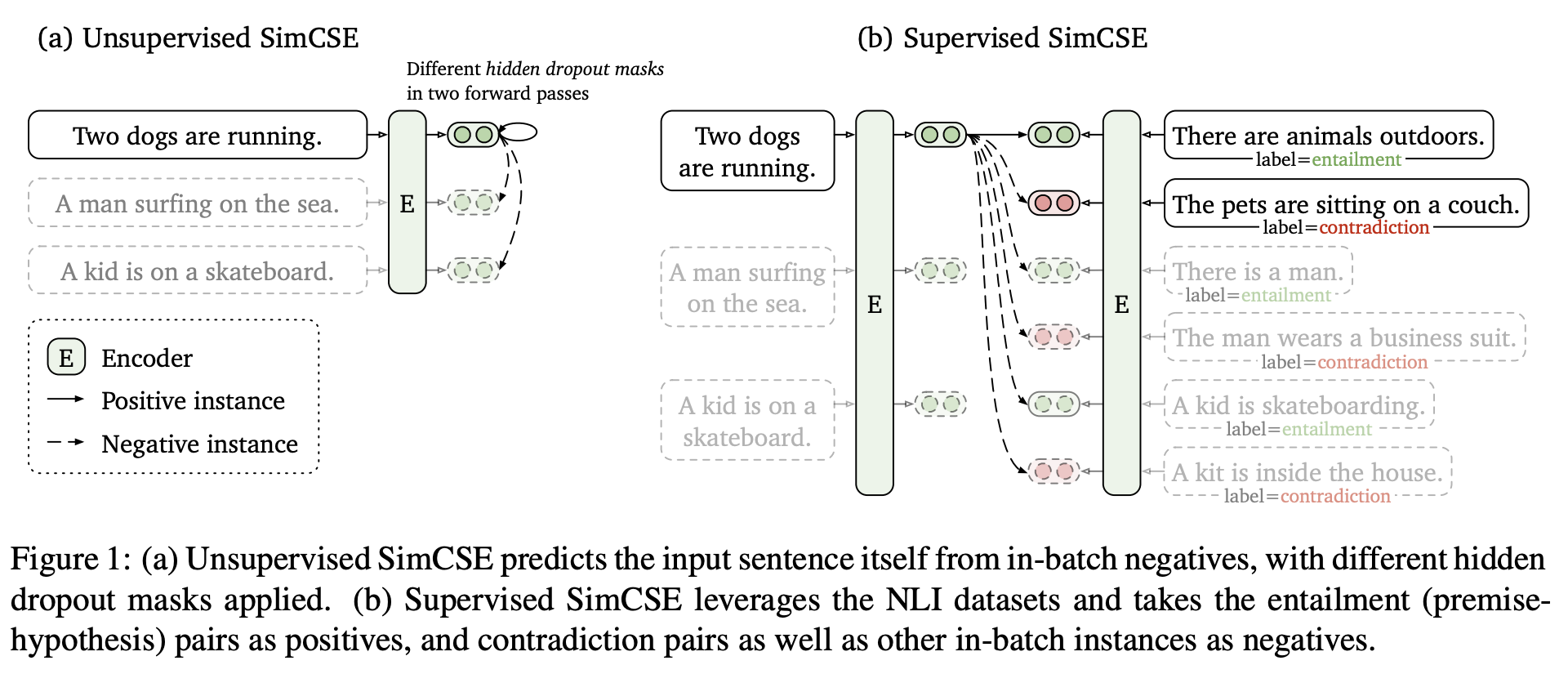
본 논문은 2022년에 프린스턴 대학교 연구진이 발표한 논문이며, 논문에서 제안한 Augmentation 기법과 Positive/Negative Pair를 구축하는 방법이 굉장히 단순하지만 신박하다. 기존에는 시퀸스의 단어를 순서를 재배치하거나, 단어를 일부 삭제하는 등의 방법이 적용이 되었지만, 해당 방법들은 문장의 의미를 손상시킨다는 가장 큰 문제가 있었다. 이에 따라 저자들은 기존의 입력 문장을 Augmentation 하는 방식 대신, 드롭아웃(dropout)을 활용해 미세한 노이즈(noise)를 주는 새로운 방법을 제안했습니다.
이러한 아이디어를 바탕으로, 논문은 Unsupervised 방식과 Supervised 방식 두 가지를 제시하였다. 먼저 Unsupervised SimCSE는 동일한 문장을 인코더에 두 번 통과시켜 Positive Pair를 생성한다. 이러한 과정에서 트랜스포머의 기본 기능인 드롭아웃이 매번 다르게 적용되어 미세하게 다른 두 개의 임베딩 벡터가 만들어지며, 이것이 바로 Positive Pair이 되는 것이다. 또한, 같은 배치 내에 있는 다른 문장들의 임베딩을 Negative Pair로 간주하게 되는 방향이다.
반면, Supervised SimCSE는 자연어 추론(NLI) 데이터셋을 활용하여 성능을 더욱 끌어올린다. 여기서는 의미적으로 유사한 entailment 관계의 문장 쌍을 Positive Pair로, 명백히 의미가 다른 contradiction 관계의 문장 쌍을 Hard Negative로 추가하여 모델이 더 섬세한 의미 차이를 학습하도록 유도한다. 결국 SimCSE는 드롭아웃이라는 단순한 기법을 핵심 아이디어로 삼아, 레이블 유무에 따라 효과적으로 문장 임베딩을 학습하는 방법을 제시하였다.

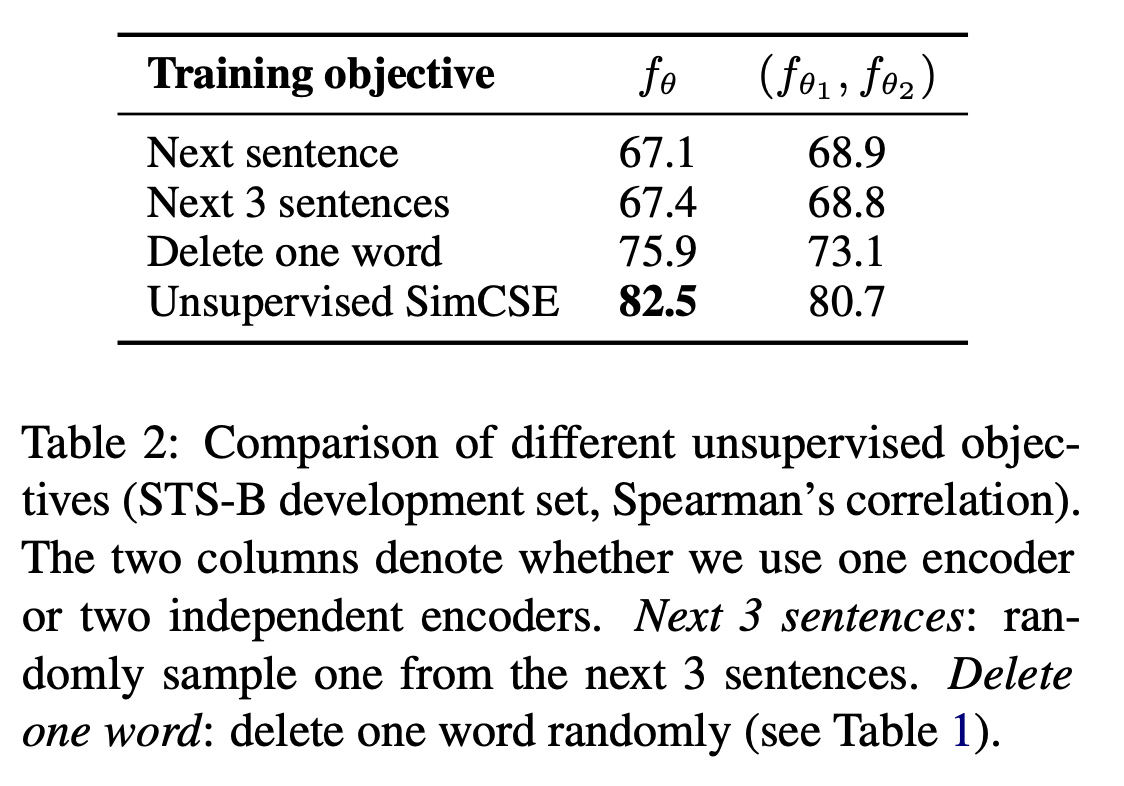
결론적으로, SimCSE는 입력 문장의 의미를 전혀 훼손하지 않으면서도, 드롭아웃을 마치 Augmentation 기법처럼 활용하여 효과적으로 Positive Pair 및 Negative Pair를 구축하였다. 이렇게 단순하면서도 강력한 아이디어는 문장 임베딩의 성능을 크게 향상시켜 많은 후속 연구에 큰 영향을 주었다.
기존 인코더의 구조적 한계를 개선한 SimCSE

기존 BERT와 같은 사전 학습된 언어 모델은 그 자체만으로 뛰어난 성능을 보이지만, 이를 통해 추출된 임베딩을 기반으로 유사도를 측정하는 데 있어 본질적인 한계점이 존재한다. 이렇게 생성된 임베딩에는 두 가지의 문제점이 존재한다.
- Alignment (정렬성) : 기존의 LLM은 마스크된 단어 예측(Masked Language Modeling)이나 다음 문장 예측(Next Sentence Prediction)하는 기법을 통해 학습된다. 이는 말 그대로 토큰 혹은 문장을 생성하는 기법이지, 문장 간의 의미적 유사성을 직접적으로 계산을 한다던가 학습하는 과정이 아니다. 따라서, 의미적으로 비슷한 문장들이 임베딩 공간상에서 반드시 가깝게 위치 해야한다는 제약조건을 반영하지 못하게 된다. 즉, Alignment이라는 것은 비슷한 문장 간의 의미적 유사성이 벡터 공간의 거리로 정렬(Alignment)되지 않은 것을 의미한다.
- Uniformity (균일성) : 핵심적인 문제로는 인코더에 태워 생성되는 임베딩 벡터들이 전체적인 임베딩 공간에 고르게 분포하지 못한다는 점이다. 모든 문장 임베딩이 특정 방향으로 치우쳐진 좁은 원뿔(Cone) 형태의 영역 안에 밀집하는 경향을 보인다고 "How Contextual are Contextualized Word Representations? 논문에서 지적하였다. 따라서, 논문에서는 이를 Anistropic 문제라고 명명하며, 임베딩 공간의 대부분을 낭비하고 표현력을 심각하게 저해하는 구체적인 원인이라고 언급하였다.
하지만, SimCSE 논문에서 제안한 Contrastive Learning 이라는 목적 함수를 통해 위에 대한 문제점을 효과적으로 완화하였다고 입증하였다. 위에서도 언급되었지만, SimSCE의 학습 방식은 의미가 같은 Positive Pair을 서로 가깝게 끌어당겨 Alignment를 직접적으로 향상시키는 동시에, 의미가 다른 Negative Pair를 서로 멀리 밀어냄으로써 뭉쳐있던 임베딩 공간을 좁은 원뿔 형태에서 전체적으로 고르게 넓혔다고 한다. 결국 이러한 "밀어냄"과 "끌어당김"이 Ainsotropy 문제를 완화하여, 당시 임베딩 관련 연구에서 SOTA를 달성한 논문이다. 이를 통해 SimCSE는 기존 인코더가 가지고 있는 구조적 한계를 극복하고 의미적으로 훨씬 풍부하고 변별력 높은 임베딩 공간을 구축할 수 있게 되었다.
'LLM > RAG' 카테고리의 다른 글
| LLAMA3.1 임베딩 모델로 변환하기 via. LLM2VEC (2) | 2025.07.13 |
|---|---|
| 사용자의 질문을 여러 개 만드는 기법 : Query Translation (Part 1) (0) | 2025.01.28 |
| 딥러닝 모델을 통한 PDF Parsing 기법 (0) | 2025.01.22 |
| RAG 성능을 좌지우지 하는 PARSING(파싱)의 한계점 (2) | 2024.11.16 |
| RAG의 패러다임(Naive RAG, Advanced RAG, Modular RAG) (0) | 2024.08.03 |