
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- qlora
- Mean squared error
- Cross Entropy Error
- deep learning
- visual instruction tuning
- 딥러닝
- leetcode
- 합성곱 신경망
- 이상탐지
- 데이터 파싱
- Time Series
- rrf
- 활성화함수
- LLM
- fp16
- 오차역전파
- LLaVA
- anomaly detection
- rag parsing
- 파인튜닝
- Non-Maximum Suppression
- pdf parsing
- gemma3
- 손실함수
- rag-fusion
- multi-query
- fine tuning
- fp32
- 활성화 함수
- bf16
- Today
- Total
Attention, Please!!!
DeepSeek-R1 처럼 "생각"하도록 LLAMA 3.2 파인튜닝 하기 본문
DeepSeek R1 모델이 출시된 이후, 이를 동일하게 구현하기 위해 다양한 연구 혹은 실험이 진행되고 있다. R1 모델이 open-source로 배포가 되면서 LLM 시장에서 큰 파급효과를 불러 일으켰다. 현재 R1 모델을 통해 생성된 데이터 셋이 많이 구축되고 있어, 이를 활용해 다른 모델들이 유사한 방식으로 "생각"할 수 있도록 훈련시킬 수 있는 가능성이 극대화 되고 있다.
이러한 데이터 셋을 활용하면 기존 LLM을 R1의 추론 능력에 맞춰 모방하도록 Fine-tuning 하는 작업이 비교적 수월해진다. 본 게시물에서는 커뮤니티에서 만든 R1 데이터 셋을 활용하여 LLM의 성능을 높이기 위한 Fine-Tuning with Adapter에 대해 알아보도록 하고자 한다. DeepSeek-R1에서 적용되었던 GRPO(Group Relative Policy Optimization) 방식 보다 접근성이 좋고 비용적인 측면에서 효율적인 SFT(Supervised Fine Tuning)을 활용하고자 한다. GRPO 방식에 대해서는 추후 다뤄보도록 하겠다.
1. Datasets Generated by DeepSeek-R1
커뮤니티에서 R1 모델을 활용해 다양한 데이터 셋을 만들었지만, 본 게시물에서는 cognitivecomputations/dolphin-r1의 데이터 셋에서 "deepseek-reasoning" subset을 활용해보고자 한다. 이는 DeepSeek-R1 모델에 의해 생성 되었으며 총 300,000 개의 샘플을 포함하고 있다. 하지만 여기에서 조금 손 봐야할 부분이 있다.
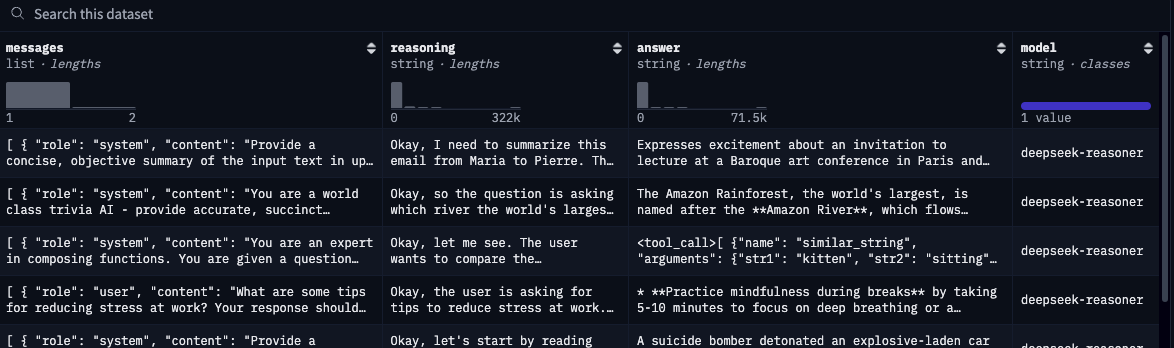
"Message" 컬럼을 살펴보면, 데이터 셋의 정보가 정리된 방식이 일반적인 데이터 셋의 형식과 다르다. 보통 데이터 셋은 "질문"과 "답변" 처럼 명확하게 나뉘어 있어야하는 반면에 dolphin-r1의 데이터 셋은 [{"role": "system", ...}, {"role": "user", ...}] 형식으로 구성되어 있다. 이러한 형식의 문제점은 TRL의 Trainer들이 원하는 데이터 형식의 구조와 맞지 않는다는 것 이다. TRL은 대체적으로 "Instruction"과 "response"가 명확하게 나뉘어야한다.
이를 조금 더 직관적으로 설명하면 다음과 같다. 현재 사용하고자 하는 cognitivecomputations/dolphin-r1 데이터 셋을 먼저 살펴보자.
[
{
"role": "system",
"content": "친구에게 간단한 인사와 질문이 담긴 메시지를 작성해."
},
{
"role": "user",
"content": "안녕 민수야,\n잘 지내? 나 다음 주에 서울 간다고! 서울에서 맛있는 음식점이나 놀 곳 추천해줄 수 있어?"
}
]
여기에서의 문제점은 "role" 이라는 키를 기반으로 질문과 답변이 나뉘어져 있고, 리스트 안에 두 개의 객체가 존재해서 TRL이 이에 대해 이해하는 데 큰 어려움을 가진다. TRL은 아래의 형식처럼 질문과 답변이 한 줄이거나 명확하게 나뉜 것을 선호한다.
# 1. instruction과 response를 한 덩어리로 만들기.
{
"text": "시스템: 친구에게 간단한 인사와 질문이 담긴 메시지를 작성해.\n사용자: 안녕 민수야,\n잘 지내? 나 다음 주에 서울 간다고! 서울에서 맛있는 음식점이나 놀 곳 추천해줄 수 있어?"
}
# 2. instruction과 response으로 명확하게 나누기.
{
"instruction": "친구에게 간단한 인사와 질문이 담긴 메시지를 작성해: 안녕 민수야,\n잘 지내? 나 다음 주에 서울 간다고! 서울에서 맛있는 음식점이나 놀 곳 추천해줄 수 있어?",
"response": "안녕 민수야! 나도 잘 지내. 서울 오면 강남에 있는 '맛집 123' 가봐, 거기 떡볶이 죽여줘. 놀 곳은 홍대 추천할게!"
}
너무나도 당연한 이야기지만, 본 게시물은 보는 분에게 조금이나마 도움이 되었으면 하여 설명드리고자 합니다. 위와 같은 방식으로 나눈 방식, 즉 질문만 있는 데이터는 SFTTrainer에 적합하지 않지만, GRPO 혹은 DPO에는 적합합니다. SFTTrainer은 질문과 답변이 함께 있어야 학습이 가능하지만, GRPO와 DPO는 질문만으로도 훈련이 원할하게 이루어질 수 있다는 것!
데이터 전처리 방법
본론으로 돌아와서 현재 사용하고자 하는 cognitivecomputations/dolphin-r1 데이터 셋의 "message" 컬럼에는 질문만 존재하고, 답변이 없습니다. 위에서 언급한 바와 같이 SFTTrainer는 "질문" 과 "답변"이 있어야 "이 질문에는 이렇게 답해" 라는 것을 배울 수 있다. 이에 "reasoning" 및 "answer"를 하나로 묶는 작업이 필요하다. 전처리 방법과 코드는 다음과 같다:
- "reasoning"과 "answer"를 하나로 묶어서 <think>...<think>\n\n 형태로 만든다.
- 그 결과를 "messages"에 새로운 항목으로 추가하고, 역할(role)은 "assistant"로 설정한다.
- 마지막으로 "messages"를 chat template으로 변환하여 "text" 라는 새로운 필드를 만든다.
from datasets import load_dataset
import multiprocessing
# 데이터셋 업로드
dataset = load_dataset(
"cognitivecomputations/dolphin-r1",
config_name='reasoning-deepseek',
split='train[:30000]'
).train_test_split(test_size=0.1)
# 토크나이저
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-llama-7b")
def format_message_column(row):
"""reasoning과 answer를 합쳐 messages에 추가하고 text 생성"""
assistant_content = f"<think>{row['reasoning']}</think>\n\n{row['answer']}"
row['messages'] = row['messages'] + [{
'role': 'assistant',
'content': assistant_content
}]
# 토큰화된 텍스트 생성
row['text'] = tokenizer.apply_chat_template(
row['messages'],
tokenize=False
)
return row
# 병렬 처리를 사용하여 train 및 test 데이터 변환
for split in ['train', 'test']:
dataset[split] = dataset[split].map(
format_message_column,
num_proc=multiprocessing.cpu_count(),
load_from_cache_file=False,
desc=f'{split} 분할 처리 중'
)
2. Using DeepSeek-R1 Speical Tokens
LLM을 파인튜닝할 때, 토크나이저(Tokenizer)을 어떻게 설정하느냐에 따라 모델의 성능과 출력 형식이 달라질 수 있다. 본 게시물에서 사용하는 DeepSeek-R1와 같은 <think> 및 </think> 특수 토큰들을 사용할 경우, 어떤 토크나이저를 사용할 수 있는지에 대해 알아보고자 한다.
- DeepSeek-R1의 토크나이저: 해당 토크나이저는 구조적 추론 및 수리적 처리에 대해 최적화되어 있다. 만약 Llama 혹은 Qwen 계열의 모델을 사용하다면, 다음의 사전 훈련된 토크나이저를 별도의 수정없이 재사용할 수 있다: deepseek-ai/DeepSeek-R1-Distill-Llama-70B or deepseek-ai/DeepSeek-R1-Distill-Qwen-32B.
- 기존 LLM의 토크나이저 수정: 특정 특수 토큰(<think>, </think>)을 추가하여 모델이 이를 인식하도록 만들고 싶은 경우에는 기존 LLM의 토크나이저에 특수한 토큰을 추가하면 된다.
- 일반적인 토크나이저 사용: <think>와 </think> 에 대해 특수 토큰이 아닌 일반 토큰으로 취급한다. 조금 더 쉽게 풀어보자면, <think>와 </think>는 모델이 "이건 추론 과정이야"라고 인식할 수 있도록 특별히 정의된 토큰을 사용해야하 지만 토크나이저를 수정하지 않고 그냥 쓰게 된다면 모델은 그냥 평범한 단어(강아지,고양이)등과 같이 이해하게 된다. 이러한 방법은 운이 좋다면 일부 경우에 작동할 수 있지만, post-training할 때는 이상적이지 않다.
본 게시물에서는 기존 LLM의 토큰나이저를 수정해서 진행해보고자 한다. 그럼 토크나이저를 어떻게 설정했는지에 대해 알아보고자 한다. 그 전에 패딩 토큰과 커스텀 토큰에 간략하게 짚고 넘어가보고자 한다.
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-3B-Instruct")
tokenizer.pad_token = "<|finetune_right_pad_id|>"
tokenizer.pad_token_id = 20250305
tokenizer.padding_side = 'right'
tokenizer.vocab[128011] = '<think>'
tokenizer.vocab[128012] = '</think>'
(i) Padding Token
패딩 토큰은 입력 시퀀스의 길이를 맞추기 위해 추가되는 특수 토큰이다. 트랜스포머 모델은 모든 토큰을 한 번에 처리(병렬 처리)하기 때문에, 입력 시퀀스가 동일한 길이를 가져야한다. 특히 학습이나 추론 시 여러 샘플을 하나의 배치로 묶어 처리할 때, 시퀀스 길이가 다르면 효율적으로 계산할 수 없다.
예를 들어:
- 문장 A: "I like to study" (4 토큰)
- 문장 B: "Hello" (1 토큰) → "Hello [PAD] [PAD] [PAD]"
문장 B에 패딩 토큰 3개를 추가해 문장 A와 길이를 맞춘다. 여기서 패딩 토큰은 "의미 없음"을 나타내며, 모델이 이를 무시하고 실제 데이터에만 집중하도록 한다. 이는 어텐션 마스크를 통해 패딩과 실제 토큰을 구분함으로써 가능하다. LLaMA와 같은 Auto-Regressive 모델은 기본적으로 패딩 토큰을 따로 정의하지 않는다. 대신 시퀀스 끝을 나타내는 <EOS> 토큰을 패딩으로 사용하는 경우가 많다. 하지만 파인튜닝에서는 문제가 생길 수 있다. 예를 들어, "Hello <EOS> <EOS> <EOS>"처럼 <EOS>를 패딩으로 쓰면, 이것이 문장의 끝인지 단순히 길이를 맞춘 패딩인지 구분하기 어렵다. 이런 의미적 혼동을 피하기 위해, 이 글에서는 <EOS> 대신 <finetune_right_pad_id>라는 별도의 패딩 토큰을 사용한다.
(ii) Reserved Token
위 코드에서 tokenizer.vocab은 토크나이저의 어휘 사전을 의미한다. LLaMA 3.2 모델의 어휘 사전은 약 128,000개의 토큰으로 구성되며, 기본적으로 0부터 127,999까지의 ID를 사용한다. 이때 128,001부터 128,255까지의 범위는 "Reserved Token"이라고 부르며, 사전 학습된 토큰에 포함되지 않은 공간이다. 이러한 "Reserved Token" 영역은 사용자가 추가적으로 새로운 토큰을 정의할 수 있도록 예약된 공간으로, 파인튜닝이나 특정 태스크에 맞춘 커스터마이징에 활용될 수 있다.
12,8011에 <think> 토큰을, 128012에 </think> 토큰을 추가한다. 이렇게 함으로써 토크나이저는 <think>와 </think>를 새로운 토큰으로 인식하게 되고, 이는 파인튜닝에서 사고 과정이나 구조적 태스크를 표현하는 데 사용될 수 있다.
3. Training LLaMA to "THINK"
위 내용에서 "Reserved Token" 새로운 토큰 <think> 및 </think>를 LLaMA3.2 모델에 추가하였다. 하지만 여기에서 추가적으로 고려해야할 점이 있다. 사용자가 임의로 정의한 "Reserved Token"은 사전 학습된 모델의 어휘에 존재하지 않는 토큰이다. 따라서 기존의 Token Embedding과 Language Modeling Head는 이 토큰에 대한 정보가 없어 이를 학습시키지 않으면 모델이 <think>를 의미 있는 토큰으로 인식하지 못하게 된다. 조금 더 직관적인 예시는 아래와 같다:
만약 "스파게티" 만드는 법을 이미 아는 요리사라고 가정해보겠다. "토마토 스파게티" 주문이 들어와서 기존 레시피에 토마토 소스를 추가로 넣는 식으로 조리하는 것이 Supervised Fine-Tuning (SFT)이 될 것 이다. 하지만 여기에서 새로운 토큰 <think>와 </think> 들을 추가한다는 것은 완전히 새로운 재료를 레시피에 넣는 것과 같다. 예를 들어, "스파게티"에 "김치"라는 재료를 추가한다고 하면, 기존 레시피에 없던 재료이니, 요리사는 이에 대해 어떻게 다뤄야 하는지 전혀 모르는 상태이다. 이대로 요리를 하면 김치가 따로노는 스파게티를 만들게될 것 이다. 즉, 모델에서 "두 핵심 구성 요소" 라는 건 요리사의 재료 이해 능력 (Token Embedding)과 요리 완성 기술(Language Modeling Head)을 뜻한다.
만약 전체 파인튜닝(Full Fine-Tuning)을 한다면, 모든 부분 (Token Embedding, Transformer Layer, Language Modeling Head)이 업데이트되니까 가 자연스럽게 학습되어 무시해도된다. 하지만 이러한 방법은 메모리와 계산 자원이 많이 필요하기 때문에... 현실적으로는 불가능한 경우가 대부분이다.
간단하게 요약하자면, LLaMA3.2 모델이 "Reserved Token"에 대해 이해할 수 있도록 Token Embedding과 Language Modeling Head에 대해 재학습을 수행해야한다. 이때 Transformer Layer는 재학습하지 않는 이유는 메모리와 계산 자원을 절약하기 위해 LoRA 어댑터로 새 토큰의 문맥에 대해 학습이 가능하기 때문이다.
#LoRA 설정
peft_config = LoraConfig(
r=16,
lora_alpha=16,
target_modules=['q_proj', 'v_proj', 'k_proj'],
modules_to_save=['embed_tokens', 'lm_head'],
task_type='CAUSAL_LM'
)
4. Evaluation of Model's Ability to "THINK"
한번의 Epoch를 돌린 후, 모델이 DeepSeek-R1 모델처럼 "THINK"하는지 확인하는 작업이 필요하다. 이를 위해서는 기본 모델에 Fine-Tuned Adapter를 추가해야한다. 여기에서 Fine-Tuned Adapter는 LoRA를 통해 학습된 결과물을 의미한다.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
compute_dtype = torch.bfloat16
attn_implementation = 'flash_attention_2'
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-3B-Instruct")
tokenizer.pad_token = "<|finetune_right_pad_id|>"
tokenizer.pad_token_id = 128004
tokenizer.vocab[128011] = '<think>'
tokenizer.vocab[128012] = '</think>'
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-3.2-3B",
device_map={"": 0},
attn_implementation=attn_implementation,
torch_dtype=torch.bfloat16,
)
model = PeftModel.from_pretrained(model, "./LoRA_R1/checkpoint-843/")
****본 게시물에 대한 코드가 필요하시다면, 댓글 남겨주세요****
'LLM > Fine-tuning' 카테고리의 다른 글
| Gemma 3 모델 파인튜닝(LoRa and QLoRA) 해보기 (0) | 2025.04.01 |
|---|---|
| Reasoning 기반 LLM 저렴하게 Fine-Tuning 하는 방법 (0) | 2025.02.26 |