
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- rag parsing
- 오차역전파
- LLM
- 활성화함수
- qlora
- anomaly detection
- 딥러닝
- 시계열
- pdf parsing
- leetcode
- 손실함수
- rag-fusion
- deep learning
- nlp
- gemma3
- 활성화 함수
- 데이터 파싱
- 합성곱 신경망
- 퍼셉트론
- Non-Maximum Suppression
- Time Series
- Mean squared error
- visual instruction tuning
- multi-query
- rrf
- 이상탐지
- 파인튜닝
- Cross Entropy Error
- LLaVA
- fine tuning
- Today
- Total
Attention, Please!!!
Gemma 3 모델 파인튜닝(LoRa and QLoRA) 해보기 본문
Gemma 3 모델을 완전하게 파인튜닝하려면 80GB VRAM을 지원하는 고성능 GPU가 필요하다. 그러나 LoRA를 기반으로 파인튜닝할 경우, 1B 및 4B 모델은 24GB VRAM이 요구되며, 27B 모델은 54GB VRAM이 필요하다. 다만, 27B 모델을 4비트로 양자화하면 24GB VRAM에서도 파인튜닝이 가능하지만, 시퀀스 길이가 제한되며 임베딩을 재학습할 수 없다는 단점이 있다. 이로 인해 chat template 사용 시 문제가 발생할 수 있다.
Chat template은 대화형 AI 모델이 채팅 환경에서 효과적으로 작동하도록 설계된 특정 구조를 의미하며, 일반적으로 <USER> 또는 <ASSISTANT> 같은 특별 토큰을 포함한다. 하지만 이러한 토큰이 학습되지 않으면 모델이 대화 흐름을 제대로 이해하지 못해 부정확하거나 엉뚱한 답변을 생성할 수 있다.
따라서, chat template을 목적에 맞게 활용하려면 임베딩 학습이 필수적이다. 그러나 Gemma 3의 방대한 vocabulary로 인해 파인튜닝 과정이 쉽지 않은 것이 현실이다. 1B 모델의 경우 크기가 작아 임베딩 업데이트가 가능하므로 딱히 문제가 없다. 그러나 4B 모델의 경우, Paging과 Quantized Optimizer를 사용하더라도 임베딩을 재학습하는 것은 1,024 토큰 이하의 시퀸스에서 24GB VRAM으로 파인튜닝 가능하다.
- Paging : VRAM이 부족할 때, 일부 텐서(모델 가중치, gradient, 옵티마이저 상태 등)를 RAM이나 디스크로 임시 이동시킨 후, 필요할 때 다시 VRAM으로 불러오는 기법을 의미한다. 이러한 방법은 GPU 메모리 사용을 효율적으로 관리하여 더 큰 모델이나 배치 크기로 학습을 진행할 수 있게 한다.
- Quantized Optimzer: 옵티마이저는 학습 과정에서 현재의 gradient뿐만 아니라 이전 gradient들의 누적값도 함께 고려하여 모델의 가중치를 업데이트한다. 또한, gradient의 변화량을 제곱한 값의 평균(2차 모멘텀)과 스케일링 팩터(Scaling Factor) 같은 추가 정보를 활용하여 최적화를 수행한다. 이 과정에서 옵티마이저는 모델의 모든 가중치에 해당하는 상태 정보를 저장하게 된다. 이에 옵티마이저가 저장하는 추가적인 정보(모멘텀, 스케일링 팩터 등) 대해 양자화를 하여 학습 가능한 최대 모델 크기를 확장하는 것이다.
더불어, 12B 혹은 27B 모델 같은 경우에는 양자화가 필수적이며, 이때 QLoRA를 적용하는 것이 굉장히 합리적이다. 이에 본 게시물에서는 QLoRA를 기반으로 Gemma3-12b-it을 파인튜닝 해보고자 합니다.
Settings for Fine-Tuning Gemma 3
Gemma 3 모델은 비교적 다른 모델에 비해 파인튜닝하기 굉장히 단순하다. 본 게시물에서는 QLoRA를 기반으로 파인튜닝한다. LoRA는 LLM을 효율적으로 파인튜닝하기 위한 기법으로, 모델의 전체 파라미터를 업데이트하는 대신 특정 모듈(Attention Layer)에 Low-Rank matrix를 추가해 학습하게 된다. 이때의 이점은 low-rank matrix를 추가함으로써, 메모리 사용량을 줄이고, 훈련 속도를 높이며, 원래 모델의 일반화 능력을 유지할 수 있다. 파인튜닝 과정에서 LoRA가 적용될 모듈을 선택할려면, 해당 모델의 아키텍처를 이해하고 특정 레이어를 대상으로 해야한다.
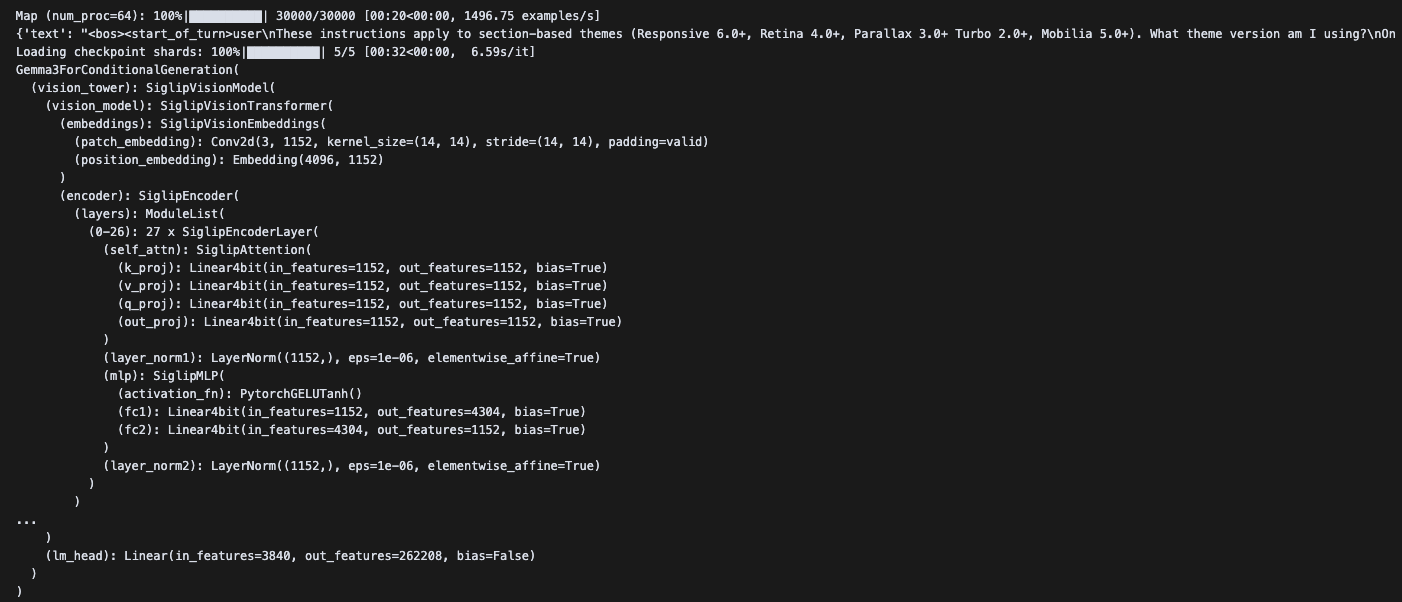
따라서, Gemma3ForConditionalGeneration() 함수를 통해 Gemma3 모델의 아키텍처를 살펴보면, (self_attn) 레이어가 어떻게 구성이 되어있는지 알 수 있다.
Gemma3ForConditionalGeneration(
(vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(4096, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipAttention(
(k_proj): Linear4bit(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear4bit(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear4bit(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear4bit(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear4bit(in_features=1152, out_features=4304, bias=True)
(fc2): Linear4bit(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
...
)
(lm_head): Linear(in_features=3840, out_features=262208, bias=False)
)
)<Gemma 3 아키텍처>
LoRA는 모델의 특정 모듈에 저랭크 매트릭스를 추가해 파인튜닝하는 방법이다. 이를 구현하려면 PEFT(Parameter-Efficient Fine-Tuning) 라이브러리를 사용해야 하며, 이 라이브러리는 LoRA 기반 파인튜닝을 제어하고 최적화할 수 있는 도구이다. PEFT 라이브러리를 사용하면 peft_config 설정을 통해 LoRA의 동작을 상세히 정의할 수 있게 된다.
peft_config는 LoRA가 어떤 모듈에 적용될지, 저랭크 매트릭스의 크기나 학습 파라미터는 어떻게 설정할지 등을 지정하는 역할을 힌다. 즉, peft_config를 통해 LoRA가 학습해야 할 대상과 학습 방식을 조정할 수 있습니다. 따라서 LoRA를 효과적으로 사용하려면 peft_config를 반드시 설정해야 하며, 이를 통해 모델이 새로운 데이터나 작업에 적응하도록 학습할 방향성을 명확히 할 수 있다.
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.05,
r=16,
bias="none",
task_type="CAUSAL_LM",
target_modules= ['k_proj', 'q_proj', 'v_proj', 'o_proj', "gate_proj", "down_proj", "up_proj"],
modules_to_save=['embed_tokens', 'lm_head'] #because of the chat template potentially containing untrained special tokens, we need to retrain the embeddings
)<LoRA based on peft_config>
대부분의 LLM(LLaMA, Mistral 등)은 토크나이저에 PADDING TOKEN이 기본적으로 포함되어 있지 않아, 별도로 정의하고 처리해야 하는 경우가 흔하다.
Padding Token에 대해 궁금하시다면, 아래의 게시물 참조 부탁드립니다.
2025.03.08 - [LLM/Fine-tuning] - DeepSeek-R1 처럼 "생각"하도록 LLAMA 3.2 파인튜닝 하기
DeepSeek-R1 처럼 "생각"하도록 LLAMA 3.2 파인튜닝 하기
DeepSeek R1 모델이 출시된 이후, 이를 동일하게 구현하기 위해 다양한 연구 혹은 실험이 진행되고 있다. R1 모델이 open-source로 배포가 되면서 LLM 시장에서 큰 파급효과를 불러 일으켰다. 현재 R1 모
g3lu.tistory.com
하지만, Gemma 3 경우, 토크나이저에 패드 토큰이 default로 설정되어 있어, 파인튜닝하기 굉장히 편리하다. 하지만, 파인튜닝을 할때, 처리해줘야 하는 것이 하나 있다. Gemma 3의 Technical Report에 따르면, 토크나이저를 인스턴스화할 때 add_bos = True 설정하는 것이 유일하다. 여기에서 BOS(Beginning of the Seqeunce) 토큰이 하는 역할은 말 그대로 입력 시퀸스의 시작을 표시하는 토큰이다.
tokenizer.chat_template = AutoTokenizer.from_pretrained("google/gemma-3-12b-it", add_bos=True).chat_template<adding BOS Token in the tokenizer>
Gemma 3는 기본적으로 두 가지의 버전의 모델을 제공한다.
- pre-trained model: Gemma 3의 기본 버전(google/gemma-3-4b)은 일반 텍스트 데이터를 기반으로 훈련되었으며, 여기에는 chat template이 기본적으로 포함되어 있지 않다. 이 모델의 토크나이저는 일반적은 토큰화 작업에 적합하지만, 일반적으로 instruction dataset을 기반으로 pre-trained 모델을 파인튜닝할 땐, 별도로 토크나이저를 수정해야하는 번거로움이 있다.
- instruction tuning model: "google/gemma-3-4b-it"와 같은 instruction tuning 버전은 위에 언급했던 것과 같이 chat template이 포함되어 있다. 이는 instruction과 response을 처리하는데 가장 적합하다.
1. Instruction tuning model를 사용할 경우
model = Gemma3ForConditionalGeneration.from_pretrained("google/gemma-3-4b-it")
tokenizer = AutoTokenizer.from_pretrained("google/gemma-3-4b-it", add_bos=True)
Instruction Model은 오직 채팅 관련 작업(챗봇)에 적합하면, 다른 일반 텍스트 처리 기능(질의 응답, 요약, 변역 등)이 필요하지 않을 경우에 사용하는 것이 좋다.
2. Pre-trained model를 사용할 경우
tokenizer = AutoTokenizer.from_pretrained("google/gemma-3-4b", add_bos=True)
tokenizer.chat_template = AutoTokenizer.from_pretrained("google/gemma-3-4b-it", add_bos=True).chat_template
Gemma 3 Technical Report를 살펴보면, "For instruction tuning, we recommend using the chat template from the instruct version while retaining the base model's tokenizer for compatibility" 라는 문장이 있다. 이처럼 pre-trained 모델을 기반으로 instruction 기반의 데이터 셋을 파인튜닝할 땐, 위 코드처럼 Pre-trained 모델의 토크나이저를 사용하고, Instruction tuning 모델에서의 chat template을 불러오는 형식으로 토크나이저를 사용해야한다.
대체적으로 파인튜닝을 하는 이유는 여러 목적을 달성하기 위함이다. 예를 들어, 오로지 순수하게 사용자와의 대화만 처리하는 챗봇을 개발하는 일은 대부분 없을 것이다. 챗봇을 통해 뉴스 기사를 요약한다거나 아랍어를 번역한다거나와 같이 다양한 작업을 수행할 수 있는 챗봇이 효율적일 것이다.
pre-trained 모델의 토크나이저를 로드하여 기본 설정(패드 토큰, BOS 토큰)을 유지하면서도, Instruction-tuning 모델의 chat template를 그대로 가져와서 pre-trained 토크나이저에 적용하면, 여러가지 작업 수행 가능한 챗봇을 개발할 수 있다. 굉장히... 단순하며, 실용적이다. 감사합니다 구글!
Result
fine_tune("google/gemma-3-12b-pt", batch_size=1, gradient_accumulation_steps=32, LoRA=False, QLoRA=True)
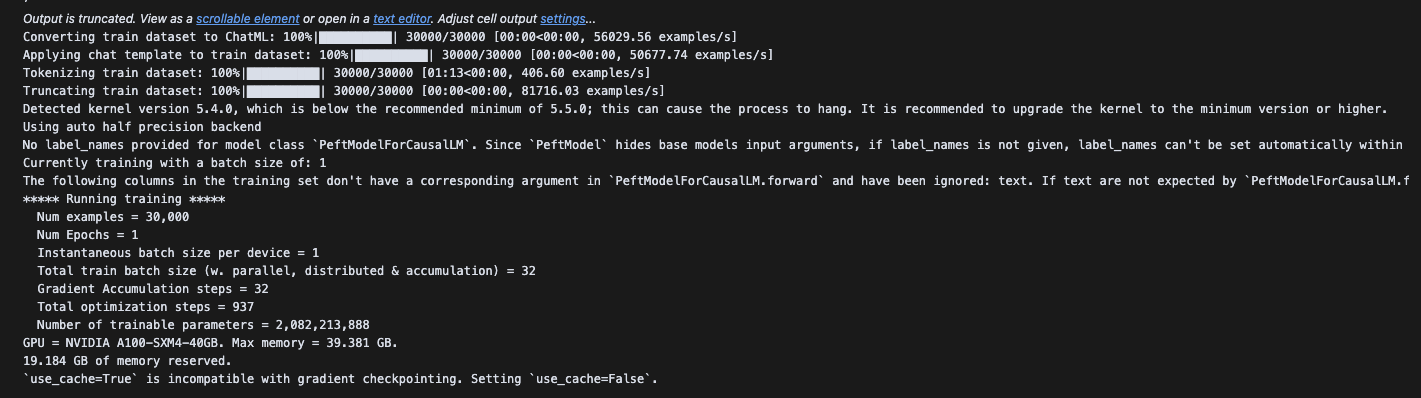
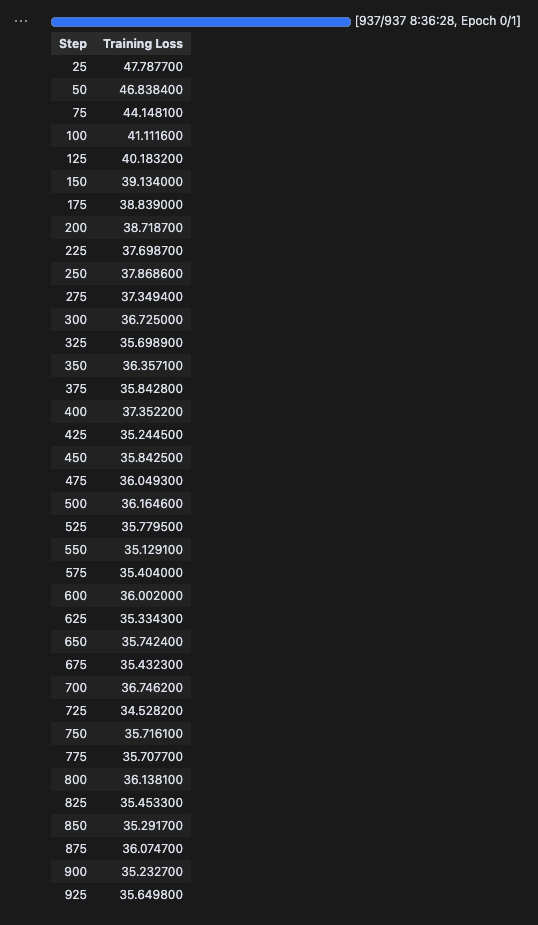
참고로 A100 40GB GPU 사용해서 총 517.04분이 소요되었으며, 메모리는 22.041GB 사용되었다.
'LLM > Fine-tuning' 카테고리의 다른 글
| DeepSeek-R1 처럼 "생각"하도록 LLAMA 3.2 파인튜닝 하기 (1) | 2025.03.08 |
|---|---|
| Reasoning 기반 LLM 저렴하게 Fine-Tuning 하는 방법 (0) | 2025.02.26 |