
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 데이터 파싱
- visual instruction tuning
- LLaVA
- Time Series
- Non-Maximum Suppression
- 이상탐지
- Mean squared error
- qlora
- pdf parsing
- bf16
- 활성화함수
- 활성화 함수
- 오차역전파
- deep learning
- 딥러닝
- 합성곱 신경망
- rrf
- rag-fusion
- multi-query
- fp32
- gemma3
- fp16
- rag parsing
- anomaly detection
- Nested Learning
- Cross Entropy Error
- 파인튜닝
- LLM
- LLM 패러다임
- fine tuning
- Today
- Total
Attention, Please!!!
vLLM이 도대체 뭘까? (via. PagedAttention) 본문
대규모 언어 모델이 다양한 분야에서 활용되면서, 학습된 모델을 실제 서비스에서 효율적으로 운영할 수 있는 추론하는 방법이 그 어느 때보다 중요해지고 있다. 무지막지한 성능의 LLM을 개발하는 것만큼이나, 이를 빠르고 비용적인 측면에서 효율적으로 사용하는 것이 어찌보면 핵심적이다. 이러한 LLM 추론 환경의 중심에는 vLLM과 Ollama라는 두 개의 강력한 오픈소스가 존재한다. 하지만, 둘 간의 지향하는 목표가 근본적으로 다르다. vLLM은 서버 환경에서 다수의 요청을 동시에 처리하며 처리량을 극대화하는 데 최적화 되어 있는 반면, Ollama는 개발자 개인의 컴퓨터에서 모델을 쉽고 간편하게 실행하는 데 중점을 둔다. 이처럼 사용하는 목적이 굉장히 다르기 때문에, 적절한 상황에 맞춰 사용하는 것이 중요하다. 따라서, 본 게시물에서는 간단한 Ollama에 대해서는 다루지 않고, vLLM에 대해 심층적으로 다루고자 한다.
vLLM에 대해 알아보기 (via. PagedAttention)
모든 대규모 언어 모델의 근간에는 Transformer 아키텍처가 자리 잡고 있다. 이는 굉장히 뛰어난 성능을 자랑하지만, 모델의 추론 속도를 저하하는 결정적인 병목현상이 존재한다. 이는 모델이 단어를 하나씩 생성(디코딩)하는 과정에서 발생하게 된다. 새로운 토큰을 추론하는 과정을 살펴보면, 어텐션 메커니즘의 이전 계산 결과를 기반으로 다음 토큰을 추론하게 된다. 이때 각 토큰에 대한 Key와 Value 벡터 쌍이 캐시에 저장이 되는데, 이는 본질적으로 가변적인 크기를 가지게 된다. 문장의 길이가 길어질수록, 즉 새로운 토큰이 생성될 때마다 새로운 Key와 Value 값 벡터가 캐시에 추가되어야 한다. 하지만, LLM이 점점 더 긴 입력을 처리하게 되면서, 연산적인 부분에서 큰 어려움이 발생되고 있다. 기존에는 KV 캐시를 하나의 크고 연속적인 메모리 덩어리로 할당하여 관리하는 것이 굉장히 일반적인 방식이였다. 하지만, 이러한 방식은 두 가지의 비효율성을 초래한다.
- 메모리 과다 할당 (Over-reservation): 추론을 시작하는 시점에서 모델이 최종적으로 얼마나 긴 문장을 생성하는지 알 수 없다. 추론하는 과정에서 할당된 메모리가 모두 소진되면, 메모리 부족(Out of Memory) 오류를 발생시키며 중단되는 경험을 한번씩은 해보았을거다. 이에 따라, 이러한 문제를 방지하기 위해, 모델은 생성할 수 있는 최대 길이의 시퀸스를 기준으로 필요한 메모리 전체를 한 번에 예약을 하게 된다. 하지만, 실제 생성된 문장이 최대 길이보다 짧은 경우, 미리 할당된 메모리의 상당 부분은 사용되지 않은채로 남게 된다. 이러한 공간은 다른 요청을 위해 사용될 수 있음에도 불구하고 해당 작업이 끝날 때까지 계속 점유되기 때문에, 결과적으로 놓고 보면 GPU 메모리의 실제 사용률을 크게 떨어트리는 것이다.
- 메모리 단편화 (Fragmentation): 이는 메모리 할당과 해제가 반복되면서 사용 가능한 공간이 조각나는 현상을 의미한다. 대체적으로 서버 환경에서 GPU를 사용하는 경우, 여러 사용자의 요청이 동시에 들어오고 처리가 끝나면 메모리가 해제되는 방식으로 진행되지만, 이에 따른 문제점이 존재한다. 다양한 크기의 메모리 요청들이 처리되면서, 메모리 공간 곳곳에 할당이 되며, 요청이 끝나면 해당 메모리 블록은 해제되어 빈 공간이 되어버린다. 하지만, 이렇게 지속적으로 반복이 된다면, 전체 메모리 공간에서는 크기가 제각각인 작은 빈 공간들이 물리적으로 흩어져 존재할 경우가 굉장히 크다.
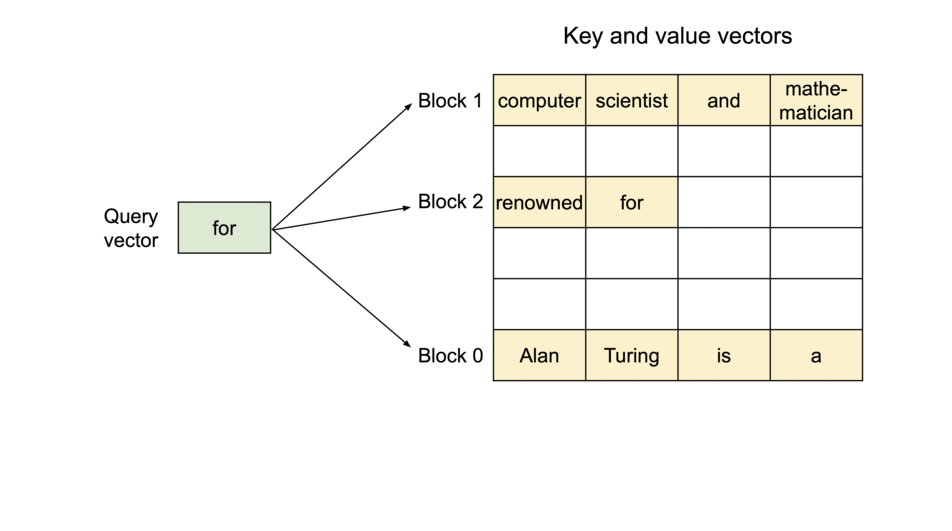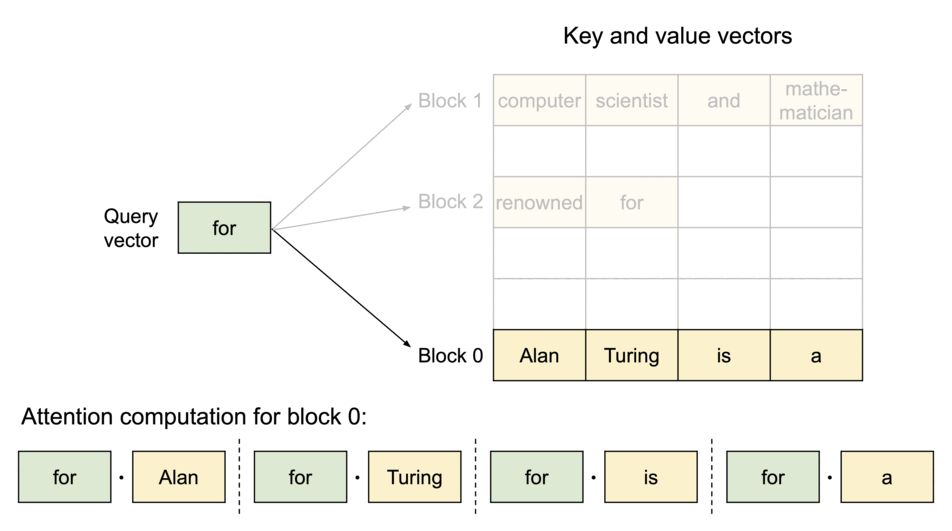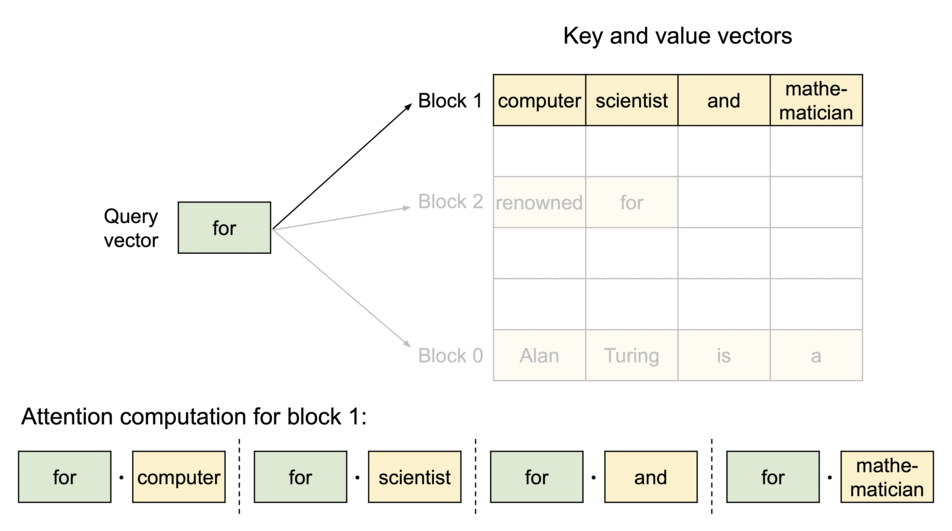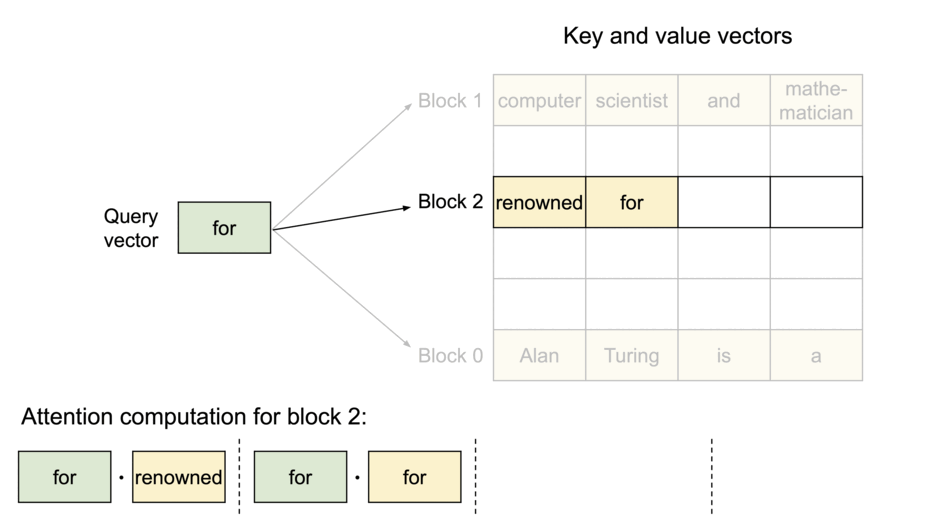
이러한 문제들을 완화하기 위해서 UC Berkely 연구진은 "PagedAttention" 이라는 방법론을 제시하였다. 그리고 이를 구현하여 누구나 쉽게 사용할 수 있도록 만든 것이 바로 vLLM이다. PagedAttention의 최종적인 목표는 key-value 텐서를 GPU VRAM의 비연속적인 공간에 더 효율적으로 저장하는 것이다. 본 논문의 연구진들은 컴퓨터 운영체제(OS)의 핵심 기술은 Virtual Memory 및 Paging 기법에서 영감을 받아 PagedAttention을 고안하였다고 한다. 그렇다면, 이러한 기법들이 실제 운영체제에서 어떻게 적용되는지 간단하게 알아보고자 한다.

컴퓨터에서 웹 브라우저, 게임 등 여러 프로그램을 동시에 실행하면, 한정된 물리적 메모리(RAM) 자원을 모든 프로그램이 나눠서 사용해야한다. 하지만, 각 프로그램은 다른 프로그램의 존재를 신경쓰지 않고, 마치 자신에게만 할당된 독립적인 메모리 공간이 있는 것처럼 작동한다. 이것이 가능한 본질적인 이유가 바로 Virtual Memory Paging 기법을 통해 일종의 착시 현상을 만들어주기 때문이다. 즉, Paging 기법으로 각 프로그램의 메모리를 잘게 조각내어 메모리 곳곳에 배치하고, Virtual Memory을 통해 이 조각들을 프로그램에게 하나의 연속된 공간처럼 보이게 만들어 주게 되는 것이다. 이러한 원리를 그대로 어텐션 메커니즘에 적용한 것이 바로 우리가 알고자 하는 PagedAttention이다
PagedAttention의 구현 방법
1. 데이터를 레고 블록처럼 나눠버리기
우선 여기에서 블록이라는 것은 단순히 개념적인 단위가 아니라, GPU 메모리상에서 실제로 고정된 크기를 갖는 물리적인 메모리 덩어리이다. 예를 들어, 하나의 블록은 16개의 토큰에 대한 Key-Value 쌍을 저장할 수 있는 크기로 정의될 수 있는 것과 같다. 만약에 LLM 모델에게 "오늘 날씨는" 이라는 프롬프트를 주면, 3개의 토큰에 대한 KV캐시가 생성이 된다. PagedAttention은 이 KV 캐시를 저장하기 위해 하나의 물리적인 블록을 할당하게 된다. 이러한 블록은 아직 N개의 토큰을 저장할 수 있는 공간이 아직 남아있다. 모델이 "매우 맑고" 라는 답변을 생성하면, 3 개의 토큰이 더 추가되어 총 6개의 토큰 정보(띄어쓰기 포함)가 첫 번째 블록에 저장이 된다. 여기에서 핵심적인 내용은 전체적인 KV 캐시를 하나의 거대한 덩어리로 저장하는 것이 아닌, 규격화된 블록 여러 개를 저장하는 것이다.
2. 빈자리 찾아 채워 넣기
이 단계는 기존 기법의 문제점인 메모리 과다 할당 (Over-reservation)과 메모리 단편화 (Fragmentation)을 해결하는 단계이다. 기존 방식이라면 처음부터 최대 길이에 해당하는 거대한 메모리를 통째로 저장하는 방식을 사용했다. 하지만, PagedAttention은 요청이 들어오면 필요한 만큼의 초기 블록만 할당한다. 그리고 토큰이 지속적으로 생성되어 할당된 블록이 꽉 차게 된다면, 이 시점에서 새로운 블록을 단 하나만 더 할당하게 된다. 여기에서 핵심적인 내용은 필요한 만큼만 사용하고 지불하는 "Pay-as-you-go" 방식과 같다라는 점이다.
3. 메모해서 기록하기
이는 흩어져 있는 블록들을 하나로 묶어주는 역할을 수행한다. 위 단계들을 거치면서 생성된 KV 캐시 블록들은 GPU 메모리 곳곳에 저장이 되어있지만, 어떤 블록이 어떠한 순서를 통해 연결되어 있는지 파악할 수 없다. 따라서, Page Table을 통해 이를 하나로 묶어주게 된다. 여기에서 핵심적인 것은 어텐션 연산을 수행하는 GPU는 페이지 테이블만 보고 흩어져 있는 블록들을 정확한 순서대로 파악할 수 있다. 이에 따라, 아무리 데이터가 멀리 떨어져 있더라도, GPU는 이를 마치 하나의 크고 잘 정리된 연속 공간처럼 인식하여 효율적으로 처리할 수 있게 된다.
요약을 해보자면, vLLM은 LLM을 추론할 때 속도와 효율성을 극대화 하는 것을 목표로 설계되었으며, 특히 동시적으로 많은 요청 혹은 매우 긴 컨텍스트를 처리하는 시나리오에 가장 적합하게 사용될 수 있다.
'LLM' 카테고리의 다른 글
| 토크나이저 학습하여 Vocabulary Size 획기적으로 줄이기 (Feat. Continued Pre-training) (1) | 2025.11.15 |
|---|---|
| GPT-OSS의 기술적 변화 (2) | 2025.10.02 |
| Padding-Free 및 Packing: 빠르고 효율적으로 LLM 파인튜닝 하기 (5) | 2025.06.26 |
| Pytorch의 Buffer를 사용해야 하는 이유 via. Attention (0) | 2025.06.23 |
| "Attention Is All You Need" 의 대항마 : Multi-Head Latent Attention (0) | 2025.05.31 |