
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Nested Learning
- Cross Entropy Error
- Mean squared error
- 데이터 파싱
- anomaly detection
- rag parsing
- rrf
- LLM
- 오차역전파
- 합성곱 신경망
- rag-fusion
- visual instruction tuning
- LLM 패러다임
- qlora
- 이상탐지
- deep learning
- Time Series
- LLaVA
- 활성화 함수
- 활성화함수
- fine tuning
- 딥러닝
- 파인튜닝
- gemma3
- Non-Maximum Suppression
- pdf parsing
- bf16
- multi-query
- fp32
- fp16
- Today
- Total
Attention, Please!!!
GPT-OSS의 기술적 변화 본문
2025년 8월 7일 기준으로 OpenAI의 open-weight 모델인 gpt-oss가 공개되었다. 이는 2019년도에 출시되었던 OpenAI의 초창기 모델인 GPT-2 이후로 공개된 모델이다. 이에 따라 본 게시물에서는 GPT-2 모델과 GPT-oss 모델 간의 차이를 깊숙하게 알아보고자 하며, 현재 출시되고 있는 대부분의 모델들의 공통점에 대해 다뤄보고자 한다. 본 게시물은 Sebastian Raschka 님의 게시물을 참고하여 작성하였음을 알립니다. 굉장히 좋은 내용이 많기 때문에 한번 방문해보시는 것을 권장 드립니다.
1. 전반적인 모델 아키텍처

2024년부터 2025년까지 공개된 모델들의 아키텍처를 살펴보면, 주요 LLM 개발사들이 대부분 동일한 기반의 아키텍처에 약간의 변형만을 추가하는 매우 비슷한 구조를 볼 수 있다. 여러 쿼리 헤드를 그룹으로 묶어 효율성을 높인 Grouped-Query Attention (GQA) 부터 LLM의 전체 크기(파라미터 수)를 키우되, 실질적으로 연산에 포함되는 파라미터를 일부 제한하여 학습 및 추론 비용을 획기적으로 줄일 수 있는 Mixture of Experts (MoE)까지 핵심적인 부분은 거의 대부분 비슷하다.
물론 트랜스포머의 한계를 극복할 수 있는 Diffusion 혹은 State Space Model 같은 새로운 아키텍처가 지속적으로 연구되고 있지만, 이를 활용하여 수천억 개 이상의 파라마터 규모로 학습되어 커뮤니티에 공개되는 사례는 아직까지 보기 힘들다. 또한, LLM의 효율성을 이끌어 내는 데 가장 중요한 것은 모델의 아키텍처 보다 어쩌면 알고리즘 혹은 데이터를 살짝 변형하는 것이 트렌드라서 그럴지도 모른다는 생각이 든다. 따라서, GPT-2 아키텍처에서 부터 GPT-OSS 까지 개선되었던 주요 기능들을 살펴보고자 하며, 현재 개발 추세에 대한 흐름을 파악하는 것을 최종적인 목표로 하는 것이 본 게시물의 핵심적인 내용이다.
2. GPT-2와의 차이점

GPT-OSS와 GPT-2는 모두 2017년 모든 사람의 심장을 뜨껍게 만든 "Attention Is All You Need" 논문에서 소개된 트랜스포머 아키텍처를 기반으로 구축된 Decoder-Only LLM이다. 여기에서 Decoder-Only LLM 이라는 것은, 기존의 트랜스포머 모델이 입력 문맥을 이해하는 인코더와 이를 바탕으로 결과를 생성하는 디코더로 구성된 것과는 다르게, 말 그대로 오직 디코더 구조만을 차용해서 텍스트를 이해하고 생성하는 모델을 의미한다. 쉽게 비유를 해보자면, 주어진 텍스트 다음에 이어질 가장 확률 높은 단어를 순차적으로 예측해 나가는 것으로 이해하면 좋을거 같다. 이러한 구조는 챗봇/요약/글 쓰기 등과 같은 생성형 작업에 매우 적합하기 때문에 GPT 시리즈 뿐만 아니라 다른 모델 시리즈에서도 많은 사용되고 있는 추세이다. 하지만, 모델이 출시됨에 따라 세부적인 내용이 약간 변형되어 나오기 때문에 GPT-2에 비해 어떠한 것이 다른지에 대해서 알아보고자 한다.
2.1 Dropout 제거하기

Dropout은 학습 중에 레이어의 활성화 값이나 어텐션 점수의 일부를 무작위로 "DROP" 시키는(즉, 0으로 설정하는) 방식으로 Overfitting을 방지할 수 있는 굉장히 전통적인 기법 중에 하나이다. 하지만, 드롭아웃은 최근에 출시되는 LLM에서는 거의 사용되지 않고 있으며, GPT-2 이후의 대부분의 모델들에서 제외되었다. 이러한 이유는 굉장히 단순한다.
일반적으로 이미지 혹은 시계열 분야에서는 한정된 데이터에서 overfitting을 방지하려고 사용되는 경우가 많지만, NLP(LLM)분야에서는 수십억 ~ 수천억 개의 파라미터를 기반으로 수조 토큰 단위의 데이터를 학습하기 때문에 overfitting이 발생할 가능성이 매우 희박하다. 오히려, 2025년 5월에 공개된 "Drop Dropout on Single-Epoch Language Model Pretraining" 논문에 따르면, Dropout을 적용하지 않은 모델들이 언어 모델링 손실, 형태-통사적 이해(BLiMP), QA(SQuAD), NLI(MNLI) 등과 같은 downstream task 측면에서 더 우수한 성능을 기록하였다.
또한, 별개로 Dropout를 적용하는 것보다 다음과 같은 방식으로 안정성을 확보하는 것이 더 효율적이다.
- LayerNorm/RMSNorm: 신경망의 각 레이어를 통과하는 데이터의 분포를 안정시키는 기법이다. 수많은 레이어를 거치면서 데이터의 평균과 분산이 계속 변하게 되는데, 이러한 변화가 지나치게 커지면 학습이 불안정해지거나 느려진다. 이에 따라, 데이터 샘플의 특징 값들의 평균을 0, 분산을 1로 정규화하는 것을 의미한다. 또한, RMSNorm은 LayerNorm를 더 단순하고 효율적으로 개선한 방식이며, 이는 LLM에서 가장 많이 채택되고 있는 기법 중 하나이다.
- Weight Decay (AdamW): 모델의 파라미터(가중치) 값이 너무 커지지 않도록 제한하는 정규화 기법 중 하나이다. 이는 손실함수에 모든 파라미터의 제곱의 합에 비례하는 패널티 항을 추가하여, 모델이 손실을 최소화하는 방향으로 만들게 하는 기법이다.
- Label Smoothing: 모델이 정답에 대해 지나치게 overconfident하는 것을 방지하는 기법이다. 일반적으로 모델을 훈련할 때, 정답 레이블의 확률은 1, 나머지는 0으로 설정하게 된다. 모델은 "1"이라는 값에 최대한 가까워지려고 학습하는데, 이러한 과정에서 정답 외 다른 선택지들은 모두 완전히 틀렸다고 학습하는 것은 유연성을 급격하게 떨어뜨릴 수 있다. 이에 모델은 하나의 레이블 뿐만 아니라 다른 것들도 아주 희박하게 가능성이 있다 라고 학습하게 되는 것을 의미한다.
- Gradient Clipping: 역전파 과정에서 그래디언트의 크기가 특정 임계값을 넘어 폭발적으로 증가하는 현상을 방지하는 기법을 의미한다. 이는 매 업데이트 단계마다 전체 그래디언트의 크기를 계산하여, 이 크기가 미리 설정한 값을 넘으면 벡터의 방향은 그대로 유지한 채 크기만 강제로 줄이는 것을 의미한다.
2.2 Rotary Postional Embedding
트랜스포머 모델은 Self-Attention 메커니즘을 통해 문장 내 단어들의 관계를 파악하게 된다. 하지만 이러한 메커니즘은 본질적으로 단어의 순서를 인식하지 못한다는 단점이 존재한다. 예를 들어, "고양이가 쥐를 쫓는다"와 "쥐가 고양이를 쫓는다"는 완전히 상반되는 의미를 가지지만, Self-Attention은 단순히 단어들의 집합으로만 문장을 보기 때문에 두 문장을 구분하지 못하게 된다. 이러한 문제점을 해결하기 위해 고안된 것이 "Positional Enconding"이다. 이는 단순하게 문장 내 단어 간의 순서를 제공하여, 모델이 각 단어의 고유한 위치를 인식하고 문장의 구조적 의미를 파악할 수 있게 해준다. 즉, 의미 정보를 담은 단어 임베딩에 순서 정보를 추가해줌으로써, 트랜스포머가 순서에 따른 문맥을 이해하도록 만들게 되는 것이다.

OpenAI의 GPT-2는 Transformer 모델의 구조를 거의 비슷하게 반영하여 모델을 구성하였는데, 여기에서 사용된 Positional Encoding 방법이 Absolute Positional Encoding이다. 이는 각 단어의 임베딩 벡터에 해당 단어의 절대적인 위치 값을 나타내는 고유한 위치 벡터를 더해주는 개념이다. 예를 들어, [w1, w2, w3]라는 시퀸스가 있다면, 각 토큰의 의미를 담은 임베딩 벡터에 그 위치를 나타내는 위치 벡터 [p1, p2, p3]를 각각 더하여 [w1+p1, w2+p2, w3+p3] 라는 새로운 입력 값을 만들어 모델에 전달하는 것이다. 하지만, 이러한 방식의 가장 큰 문제는 모델이 훈련된 최대 시퀸스 길이를 넘어서는 입력에 대한 일반화 성능이 급격하게 떨어진다는 치명적인 단점이 존재한다. 예를 들어, 모델이 최대 512개의 토큰으로만 훈련되었다면, 513번째 위치에 대한 벡터 정보는 존재하지 않는다는 것이다.
이러한 한계를 극복하기 위해 등장한 개념이 Relative Positional Encoding이다. 이에 대한 핵심적인 아이디어는 단어의 절대적인 위치 값을 알려주는 대신, Attention 계산 시 두 단어 사이의 상대적인 거리를 고려하는 것이다. 예를 들어, "고양이" 토큰의 관점에서 "쥐" 토큰이 2칸 뒤에 있다 라는 상대적 관계가 절대적인 위치보다 더 중요하다는 관점으로 설명할 수 있다. 이를 통해 절대적인 위치를 알려주면서도 위치 간의 상대적인 관계를 더욱 더 자연스럽게 인코딩하여 최대 시퀸스 길이 문제를 효과적으로 해결할 수 있다.
2.3 Swish/SwiGLU

초기 GPT 아키텍처는 당시 표준 활성화 함수였던 ReLU 대신 GELU 함수를 채택하였다. 이는 ReLU의 고질적인 문제점이 존재하였다. 구체적으로, ReLU 함수는 음수 입력값에 대해 항상 0을 출력하여 해당 뉴런의 gradient가 0이 되어버리고, 결국 학습이 멈추는 치명적인 단점이 존재한다. 반면, GELU는 부드러운 곡선 형태를 가져 모든 지점에서 안정적인 그래디언트를 보장할 수 있게되었다. 이러한 특성으로 인하여 뉴런이 비활성화되는 문제를 방지하고, 모델 전체의 학습 안정성과 성능을 크게 향상시킬 수 있다.
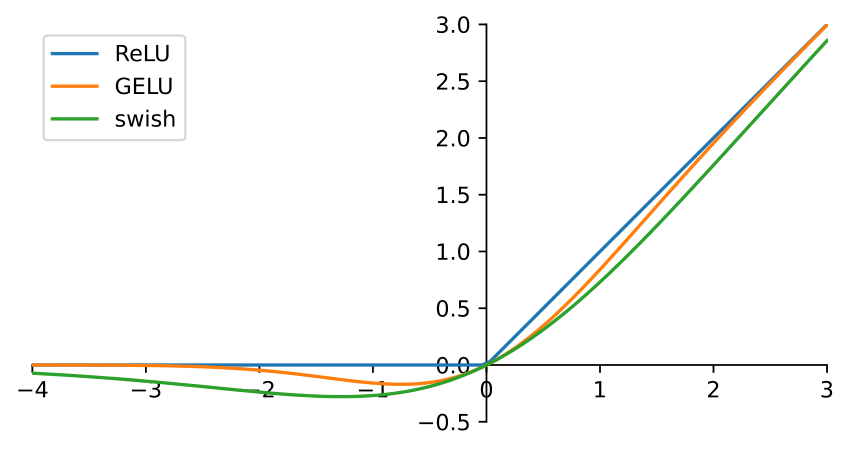
GELU 함수 같은 경우, 명칭에서 알 수 있듯이 확률론적인 접근을 통해서 고안이 되었다. 조금 더 쉽게 이야기를 해보자면, 입력 값이 주어졌을 때, 활성화 시킬까 말까? 를 결정하는 가우시안 분포를 이용해 확률적으로 모델링을 하였다. 하지만, GELU 수식에 포함된 오차함수 (erf)는 간단한 사칙연산이나 지수함수로 표현되지 않고, 다항식 근사와 같은 복잡한 과정을 거쳐 계산을 하게 된다. 그 말은 즉슨 더 많은 연산량을 필요로 하기에 Computational 측면에서 높다는 것이다.
이렇게 GELU 함수가 가진 계산 비용의 문제점을 해결하면서도 극한의 효율을 이끌어내는 함수가 바로 Swish 함수이다. Swish 함수는 SiLU (Sigmoid-weighted Linear Unit) 라고도 불리며, LLAMA를 포함한 수많은 LLM에 채택이 되었다. GELU 함수는 확률 이론에서 시작한 것과 달리, Swish는 Google Deepmind 연구진들이 수많은 후보 함수를 만들어 테스트한 결과, 가장 효과적이면서도 단순한 구조가 바로 Swish 함수이다.

Swish 함수는 Linear Component (x)과 Gating Componenet (σ(x))으로 나뉘게 되는데, Linear Componenet는 말 그대로 입력값 자체를 그대로 전달하는 선형적인 부분이고, Gating Componenet는 Sigmoid 함수의 입력 값을 0과 1 사이의 값으로 변환하는 역할(Gating)을 수행한다. 이렇게 단순한 작동 방식으로 뉴런이 비활성화되는 문제점을 개선할 뿐만 아니라, 지수함수만을 사용하기 때문에 계산이 매우 빠르고 효율적인 활성화 함수이다.

또한, 2020년도 구글 딥마인드의 Shazeer는 "GLU Variants Improve Transformer" 제목의 논문을 게재하였다. 이는 트랜스포머의 FFN을 Gated Linear Unit (GLU) 계열의 아키텍처로 교체하는 것을 통해 월등히 높은 성능과 안정성을 제고할 수 있다고 주장하였다. 여기에서 GLU는 서로 다른 선형 계층을 통과한 두 출력을 곱하는 방식으로 구현된다. 조금 더 구체적으로, 입력된 문맥을 보고 A라는 정보는 중요하니 100% 통과시키고, B라는 정보는 덜 중요하니 20%만 고려하겠다와 같이 정보의 흐름을 동적으로 제어할 수 있는 게이트 매커니즘이라고 생각하면 될거 같다.
2.4 MoE (Mixture of Experts)

일반화 성능을 극한으로 끌어올리고자 한다면, 모델의 크기를 키워야하는 것이 굉장히 일반적이다. 이에 따라 LLM 모델의 파라미터를 점진적으로 키워가는 것이 연구의 한 축을 담당하였다. 하지만, 무작정 키우게 된다면 결론적으로 LLM의 모델은 연산 속도가 매우 느려지고, 막대한 계산 비용이 발생한다. 따라서, 구글 딥마인드의 Shazeer는 2017년 "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer" 이라는 논문을 통해 이에 대한 해결점을 제안하였다.
이는 모델의 파라미터를 극한으로 끌어올리되, 실제 활성화되는 파라미터의 수를 일부만 선택적으로 사용하는 아이디어에서 착안이 되었다. 기존의 LLM (Dense Model)은 한 명이 모든 분야에 대해 빠삭한 천재라고 비유할 수 있다. LLM은 기본적으로 역사, 과학, 예술, 수학 등 모든 질문에 대한 답변을 생성할 수 있지만, "1+1"와 같은 간단한 질문에 굳이 모든 파라미터를 활성화 시켜서 계산을 해야할까? 단순하게 "수학"에 관련된 파라미터만 활용하면 되는데? 와 같은 셈이다.
MoE는 기존 트랜스포머 아키텍처의 Feed Forward Network (FFN) 부분을 여러 개의 전문가 FFN으로 대체한 구조이다.
- Experts: 이는 특별한 것이 아니라, 기존의 FFN 혹은 GLU 블록 그 자체이다. MoE에서는 이러한 블록을 8개, 16개, 64개 등과 같이 여러 개로 모듈화 하는 것이며, 각각의 블록은 서로 다른 지식과 패턴을 학습한 고유의 파라미터를 가지게 된다.
- Router: 문장에서 각 토큰이 입력될때 마다, 그 토큰의 의미를 파악하고 이에 가장 적합한 블록에 전달하는 역할을 수행한다.
이러한 Sparse Activation 방식은 모델의 총 파라미터 수를 수천억 개까지 늘려 방대한 지식을 담으면서도, 실제 연산은 일부 파라미터를 사용하므로 훨씬 작은 모델처럼 빠르고 효율적인 추론을 가능하는 방법이다.
2.5 Sliding Window Attention

기존 트랜스포머의 어텐션 메커니즘은 모든 토큰이 시퀸스 내 다른 모든 토큰을 참조하기 때문에, 시퀸스 길이가 길어질수록 계산량이 기하급수적으로 증가하는 근본적인 한계점을 지닌다. 이러한 문제를 해결하고자 Allen Institute 연구진들은 "Longformer: The Long-Document Transformer" 논문을 발간하였다. 이는 Sliding Window Attention (SWA) 방법을 통해 각 토큰이 전체 시퀸스 대신 자신의 주변, 즉 고정된 크기의 윈도우 내에 있는 이전 토큰들에만 어텐션를 부여하는 방식을 제안하였다. 이러한 접근법은 연관성이 높은 문맥은 대부분 지역적으로 분포한다는 가정을 기반하여 계산량을 제곱 (O(N^2))에서 선형 (O(N x W))으로 줄이게 된다.
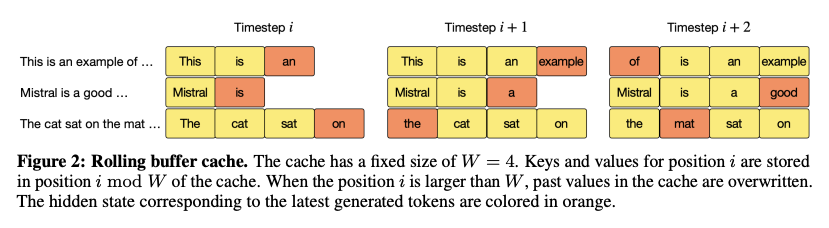
SWA를 효율적으로 구현하기 위해서는 Rolling Buffer Cache라는 핵심적인 기술이 사용된다. 이는 윈도우 크기 만큼의 이전 토큰들에 대한 Key와 Value 값을 저장하는 캐시로, 새로운 토큰이 처리될때마다 가장 오래된 Key-Value 쌍을 버리고 새로운 쌍을 추가하는 슬라이딩 방식을 기반으로 작동된다. 이를 통해 윈도우가 한 칸씩 이동할 때 겹치는 부분을 중복적으로 계산할 필요 없이 재활용하여 연산 효율성을 극대화 할 수 있게 되는 것이다.

추가적으로, 긴 입력을 메모리 제약 없이 처리하기 위해서는 텍스트를 일정한 크기의 청크 단위로 나누어 순차적으로 입력하는 과정을 거치게 된다. 이때, 가장 첫번 째 청크를 처리하여 RBC를 초기화하고 다음 연산에 필요한 값을 미리 채워 넣는 과정을 Pre-fill 이라고 한다. 이에 대한 과정이 끝나게 되면, 이후의 청크들은 RBC에 캐시된 이전 청크의 Key-Value 값을 자연스럽게 이어받아 Sliding Window 연산을 효율적으로 수행할 수 있게 된다.
'LLM' 카테고리의 다른 글
| 토크나이저 학습하여 Vocabulary Size 획기적으로 줄이기 (Feat. Continued Pre-training) (1) | 2025.11.15 |
|---|---|
| vLLM이 도대체 뭘까? (via. PagedAttention) (2) | 2025.08.03 |
| Padding-Free 및 Packing: 빠르고 효율적으로 LLM 파인튜닝 하기 (5) | 2025.06.26 |
| Pytorch의 Buffer를 사용해야 하는 이유 via. Attention (0) | 2025.06.23 |
| "Attention Is All You Need" 의 대항마 : Multi-Head Latent Attention (0) | 2025.05.31 |